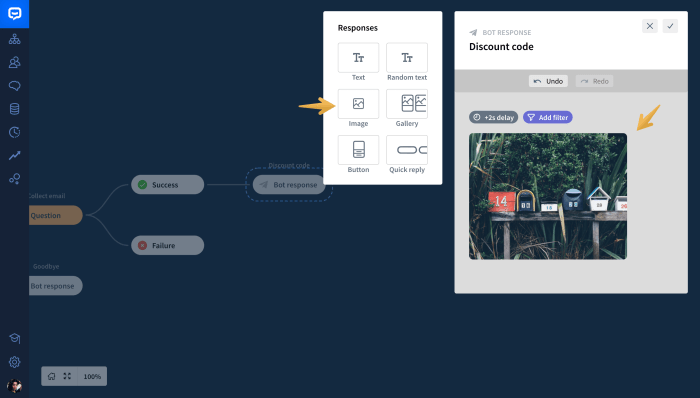
The constraints of AWS Lambda functions, particularly concerning deployment package size, present a significant challenge for developers. These limitations can impede deployment efficiency and negatively impact cold start times, especially when incorporating substantial dependencies or large codebases. This exploration meticulously dissects the problem of managing large deployment packages and presents Lambda Layers as a strategic solution.
This document will systematically analyze the use of Lambda Layers, detailing their functionality, benefits, and implementation strategies. We will examine code structuring, dependency packaging, deployment procedures, optimization techniques, and troubleshooting methods. Furthermore, advanced management techniques and real-world use cases will be presented, equipping readers with the knowledge to effectively manage large deployment packages within the Lambda environment.
Understanding the Challenge: Large Deployment Packages
AWS Lambda functions, while offering serverless scalability and ease of deployment, present challenges when dealing with large deployment packages. Understanding these limitations and their impact is crucial for optimizing function performance and deployment efficiency. The size of the deployment package directly influences cold start times and the overall agility of the development and deployment process.
AWS Lambda Package Size Limits
AWS Lambda imposes hard limits on the size of deployment packages to ensure efficient function execution and resource management. Exceeding these limits can lead to deployment failures and performance degradation.
- Unzipped Package Size Limit: The unzipped size of a Lambda function’s deployment package is a critical constraint. The exact limit varies, but it generally dictates the total size of all code and dependencies within the function.
- Zipped Package Size Limit: The zipped size of the deployment package is also limited, particularly for uploads via the console or API calls. This limit restricts the size of the archive file uploaded to AWS.
- Ephemeral Storage: Lambda functions have access to ephemeral storage in the /tmp directory. While this is not directly part of the deployment package, the total storage available is limited.
Common Scenarios Leading to Large Deployment Packages
Several factors contribute to the creation of large deployment packages, particularly in complex applications. Recognizing these scenarios is the first step towards implementing effective mitigation strategies.
- Large Dependencies: Incorporating numerous or substantial external libraries, such as machine learning frameworks (TensorFlow, PyTorch), data science libraries (Pandas, NumPy), or extensive UI frameworks, can significantly inflate the package size. These libraries often contain numerous files and dependencies, increasing the overall size.
- Large Codebase: Extensive custom code within the Lambda function itself contributes to package size. Functions that include a significant amount of source code or embedded data (e.g., large configuration files, data files) will naturally have larger packages.
- Incorrect Dependency Management: Inefficient dependency management practices, such as including unnecessary dependencies or failing to optimize dependency versions, can bloat the package size. For instance, including the entire AWS SDK when only a subset of services is used.
- Packaging Issues: Issues with the packaging process, such as including unnecessary files or directories (e.g., development tools, build artifacts) in the deployment package, can also increase the size.
Impact of Large Packages on Cold Start Times and Deployment Efficiency
The size of a Lambda deployment package has a direct impact on two critical aspects of function performance and operational efficiency: cold start times and deployment speed.
- Increased Cold Start Times: Cold starts occur when a Lambda function is invoked for the first time, or after a period of inactivity. Larger packages require more time to be downloaded, unpacked, and initialized, leading to longer cold start times. This delay can negatively impact user experience, particularly for latency-sensitive applications.
- Reduced Deployment Efficiency: Deploying large packages takes longer. This affects the speed of code updates, bug fixes, and new feature releases. The time required to upload, validate, and deploy the package increases, leading to a slower development cycle and potential delays in releasing updates.
- Storage and Transfer Costs: Larger packages may incur higher storage costs on AWS S3, where the deployment package is stored, and increased data transfer costs during deployments and function invocations.
Introduction to Lambda Layers
Lambda Layers offer a powerful mechanism for managing dependencies and code reuse within AWS Lambda functions, directly addressing the challenges posed by large deployment packages. They provide a standardized approach to packaging and sharing code, libraries, and other resources across multiple functions, significantly reducing deployment package sizes and promoting code maintainability. This approach is particularly crucial for complex applications where the same dependencies are utilized across various functions.
Defining Lambda Layers and Functionality
Lambda Layers function as a zip archive containing code, libraries, or other dependencies. These archives are uploaded to AWS and can be attached to Lambda functions. When a Lambda function is invoked, the Lambda execution environment makes the layer’s contents available to the function’s code. The function’s code can then import and utilize the layer’s contents as if they were part of the function’s deployment package, but without the size overhead.Lambda Layers are designed to work with the following process:
- Layer Creation: Developers create a zip archive containing the necessary files (e.g., Python libraries, Node.js modules, native binaries). This archive is then uploaded to an S3 bucket.
- Layer Versioning: Each upload creates a new version of the layer, allowing for version control and rollback capabilities. This is critical for managing updates and ensuring compatibility.
- Function Attachment: Layers are attached to Lambda functions via the AWS Management Console, the AWS CLI, or infrastructure-as-code tools like AWS CloudFormation or Terraform. Multiple functions can reference the same layer.
- Runtime Environment Integration: During function invocation, the Lambda runtime environment extracts the layer contents into a designated directory within the function’s execution environment (e.g., `/opt`). The runtime then makes these contents available to the function’s code through the appropriate path configurations.
- Dependency Resolution: The runtime environment handles the resolution of dependencies within the layer, allowing the function’s code to import and utilize the layer’s contents.
Benefits of Utilizing Layers for Code and Dependency Management
Employing Lambda Layers offers several significant advantages in managing code and dependencies within serverless applications. These benefits contribute to improved efficiency, maintainability, and overall development workflow.Key advantages include:
- Reduced Deployment Package Size: By centralizing dependencies in layers, the size of the function’s deployment package is significantly reduced. This leads to faster deployment times and improved cold start performance, particularly for functions with numerous dependencies.
- Code Reusability: Layers facilitate code reuse across multiple Lambda functions. Common libraries, utility functions, and configuration files can be packaged in a layer and shared, reducing code duplication and promoting consistency.
- Simplified Dependency Management: Layers provide a centralized location for managing dependencies. When a dependency needs to be updated, the layer is updated, and all functions referencing that layer automatically benefit from the update. This simplifies the process of managing dependencies and reduces the risk of version conflicts.
- Improved Maintainability: Separating code and dependencies into layers enhances code organization and maintainability. Changes to dependencies are isolated within the layer, minimizing the impact on function code. This separation of concerns promotes a cleaner and more manageable codebase.
- Faster Deployment Times: Smaller deployment packages result in quicker deployment times, accelerating the development cycle and reducing the time required to release updates. This is particularly noticeable in CI/CD pipelines.
Comparing and Contrasting Layers with Other Deployment Strategies
Lambda Layers represent one approach to managing dependencies and deployment packages in serverless applications. Other strategies exist, each with its own advantages and disadvantages. Understanding these differences is crucial for choosing the optimal deployment strategy for a specific use case. One of the main alternatives is using container images.Here’s a comparison of Lambda Layers and container images:
- Deployment Package Size: Layers excel at reducing deployment package sizes for functions that share dependencies. Container images encapsulate the entire runtime environment, including the operating system and dependencies, which can result in larger package sizes, although image optimization can mitigate this.
- Dependency Management: Layers provide a centralized mechanism for managing dependencies, simplifying updates and reducing the risk of version conflicts. Container images offer greater flexibility in managing dependencies, as they allow developers to specify the exact runtime environment and dependencies required.
- Code Reusability: Layers facilitate code reuse across multiple Lambda functions. Container images can be reused across different functions, but require more complex management and orchestration.
- Cold Start Performance: Layers can improve cold start performance by reducing deployment package sizes. Container images, particularly larger ones, can have slower cold start times. However, this can be improved through optimizations like provisioned concurrency.
- Flexibility and Control: Container images offer greater flexibility and control over the runtime environment, allowing developers to customize the operating system, install specific software, and configure the environment to their exact needs. Layers are more constrained by the Lambda runtime environment.
- Complexity: Layers are generally simpler to implement and manage for basic dependency management. Container images introduce more complexity, requiring containerization knowledge and the use of container registries and orchestration tools.
Container images, while offering greater control and flexibility, often come with a higher complexity and potentially slower cold start times. Layers are generally the more straightforward choice for sharing dependencies and reducing deployment package size when the required dependencies are compatible with the Lambda runtime environment. The choice between these approaches depends on the specific needs of the application, the level of control required, and the desired balance between flexibility and complexity.
Structuring Code for Layer Compatibility

To effectively leverage Lambda layers, a well-defined structure for your code is crucial. This organization facilitates dependency management, version control, and deployment efficiency. Adopting a structured approach minimizes deployment package sizes and optimizes function performance.
Recommended Directory Structure for Layer Code
A consistent directory structure within your Lambda layers is essential for ensuring compatibility and maintainability. This structure dictates how your code and dependencies are organized and accessed by your Lambda functions.
- The root directory of a layer should typically contain a `nodejs` or `python` directory (depending on the runtime). This directory will house your code and dependencies.
- Within the runtime-specific directory (e.g., `nodejs`), create a `node_modules` directory to hold all the required dependencies. This replicates the standard Node.js module resolution behavior. This is where your dependencies are installed and will be made available to your Lambda function.
- Your application code itself (e.g., your Lambda function handlers) can reside in a separate directory, such as `src` or `lib`, within the runtime-specific directory. This separation ensures a clear distinction between your application logic and the installed dependencies.
- Consider a structure like this example for a Node.js layer:
my-layer/
├── nodejs/
│ ├── node_modules/
│ │ ├── aws-sdk/ (or your other dependencies)
│ │ └── ...│ └── src/
│ └── my-function.js
└── ...
Strategy for Separating Application Code from Shared Dependencies
Separating application code from shared dependencies is fundamental to the effective use of Lambda layers. This segregation reduces deployment package sizes, improves cold start times, and simplifies dependency management.
- Dependency Installation: Install your dependencies directly into the `node_modules` directory within your layer. This allows Lambda to find and load these modules when the function is invoked. Using a package manager such as npm or yarn facilitates this process.
- Code Placement: Place your application code (the handler functions that your Lambda executes) outside of the `node_modules` directory. This ensures that only the required dependencies are included in the layer, minimizing its size.
- Import Statements: In your Lambda function code, import the necessary dependencies as you normally would, using `require` or `import` statements. Lambda will automatically resolve these imports from the layer’s `node_modules` directory.
- Example (Node.js): If you are using the AWS SDK, you would install it into your layer’s `node_modules`. Your Lambda function code would then import the SDK:
const AWS = require('aws-sdk');
const s3 = new AWS.S3();exports.handler = async (event) =>
// Use s3 to interact with S3
;
Method for Versioning and Managing Multiple Layer Versions
Versioning is essential for managing Lambda layers, enabling you to iterate on your dependencies and code without breaking existing functions. This allows for rollback capabilities and controlled updates.
- Versioning Scheme: Adopt a clear versioning scheme for your layers, such as semantic versioning (SemVer – MAJOR.MINOR.PATCH). This scheme clearly communicates the nature of changes (breaking, feature, or bug fix).
- Layer Creation and Updates: When creating a new layer version, increment the version number appropriately. For example, if you’ve added a new feature, increment the MINOR version. If you’ve made a breaking change, increment the MAJOR version.
- Layer ARN: The Amazon Resource Name (ARN) of a layer uniquely identifies it, including the version. The format is: `arn:aws:lambda:
: :layer: : `. This allows you to reference specific layer versions in your Lambda function configurations. - Function Configuration: When configuring your Lambda function, specify the ARN of the layer version you want to use. This ensures that your function uses the correct version of the dependencies and code. You can update the layer ARN in your function’s configuration to deploy a new version.
- Example: If your layer’s name is `my-shared-dependencies`, a possible versioning might look like:
- `arn:aws:lambda:us-east-1:123456789012:layer:my-shared-dependencies:1` (Version 1)
- `arn:aws:lambda:us-east-1:123456789012:layer:my-shared-dependencies:2` (Version 2 – added a new feature)
- `arn:aws:lambda:us-east-1:123456789012:layer:my-shared-dependencies:3` (Version 3 – bug fix)
- Rollback Strategy: If a new layer version introduces issues, you can easily roll back to a previous version by updating the layer ARN in your Lambda function configuration. This minimizes downtime and allows for a controlled recovery. Monitoring and alerting systems can help to detect issues and trigger rollbacks automatically.
Packaging Dependencies for Layers
Creating effective Lambda layers necessitates careful packaging of dependencies. The approach varies depending on the programming language used, leveraging language-specific package managers and addressing the nuances of native dependencies. This section details the process, providing practical examples for Python and Node.js.
Creating Python Layers with pip
Python layers utilize `pip`, the standard package installer for Python, to manage dependencies. The core principle involves creating a dedicated directory structure within the layer’s zip archive.To illustrate, consider a scenario where a Lambda function requires the `requests` library. The following steps Artikel the process:
- Create a working directory. This directory serves as the staging area for building the layer. For example: `mkdir python_layer`.
- Navigate into the working directory. `cd python_layer`.
- Create a `python` directory. This directory is crucial because Lambda expects Python dependencies to reside within a `python` directory at the root of the layer. `mkdir python`.
- Install dependencies using `pip`. Within the `python_layer` directory, execute the following command, ensuring the dependencies are installed into the `python` directory: `pip install -t python/ requests`. The `-t` flag specifies the target directory for installation. This command installs the `requests` library and its dependencies within the `python` directory.
- Zip the `python` directory. Navigate back to the `python_layer` directory and create a zip archive of the `python` directory. For example, using the command: `zip -r python_layer.zip python`. The `-r` flag recursively adds all files and subdirectories.
- Upload the zip file to AWS Lambda as a layer. The uploaded zip file is now a Lambda layer. When configuring the Lambda function, associate this layer. The Lambda function can then import the `requests` library.
The directory structure will appear similar to this:
python_layer/├── python/│ ├── requests/│ │ ├── __init__.py│ │ ├── ...│ ├── urllib3/│ │ ├── __init__.py│ │ ├── ...│ ├── ...├── python_layer.zip
Creating Node.js Layers with npm
Node.js layers utilize `npm`, the Node Package Manager, for dependency management. The process shares similarities with Python, focusing on creating a specific directory structure.
Consider a Lambda function requiring the `axios` library. The steps are:
- Create a working directory. For example: `mkdir nodejs_layer`.
- Navigate into the working directory. `cd nodejs_layer`.
- Create a `nodejs` directory. Lambda expects Node.js dependencies to reside within a `nodejs` directory at the layer’s root. `mkdir nodejs`.
- Initialize a `package.json` file. Inside the `nodejs` directory, create a `package.json` file. This file describes the project and its dependencies. `cd nodejs && npm init -y`. The `-y` flag accepts the default values.
- Install dependencies using `npm`. Install the desired packages, like `axios`, with the `–prefix` flag pointing to the `nodejs` directory. `npm install –prefix nodejs axios`. This ensures that `axios` and its dependencies are installed within the `nodejs/node_modules` directory.
- Zip the `nodejs` directory. Navigate back to the `nodejs_layer` directory and create a zip archive of the `nodejs` directory. For example: `zip -r nodejs_layer.zip nodejs`.
- Upload the zip file to AWS Lambda as a layer. Associate the uploaded layer with the Lambda function. The function can then `require(‘axios’)`.
The directory structure will resemble this:
nodejs_layer/├── nodejs/│ ├── node_modules/│ │ ├── axios/│ │ │ ├── index.js│ │ │ ├── ...│ │ ├── ...│ ├── package.json│ ├── package-lock.json├── nodejs_layer.zip
Handling Native Dependencies in Layers
Native dependencies, often written in languages like C or C++, present a unique challenge.
They are compiled and linked to specific operating system versions and architectures. Deploying these dependencies within a Lambda layer requires careful consideration of the Lambda execution environment.
The Lambda execution environment is based on Amazon Linux
2. Consequently, any native dependencies must be compiled or packaged for this environment. The process often involves:
- Identifying the dependency. Determine the specific native libraries required.
- Compiling or obtaining pre-compiled binaries. If the dependency source code is available, compile it on an Amazon Linux 2 instance or Docker container emulating Amazon Linux 2. Alternatively, search for pre-compiled binaries compatible with Amazon Linux 2.
- Packaging the libraries. Place the compiled libraries (e.g., `.so` files for Linux) in the appropriate directory structure within the layer, mirroring how they would be used in the application. Common locations include `lib` directories at the root of the layer or within a language-specific directory like `python` or `nodejs`.
- Setting environment variables. Configure environment variables like `LD_LIBRARY_PATH` (for Linux) within the Lambda function’s configuration to tell the runtime where to find the native libraries.
For example, if a Python function requires a native library called `mylib.so`:
- Compile `mylib.so` on an Amazon Linux 2 environment.
- Place `mylib.so` in the `python/lib` directory of the layer.
- In the Lambda function’s configuration, set the environment variable: `LD_LIBRARY_PATH=/opt/python/lib`.
Failure to correctly handle native dependencies results in `library not found` or similar errors during Lambda execution.
Deploying Layers and Lambda Functions
Deploying Lambda layers and associating them with functions is a critical step in leveraging the benefits of code reuse, dependency management, and reduced deployment package sizes. This section Artikels the process, ensuring efficient and effective integration.
Creating and Deploying a Layer
Creating and deploying a Lambda layer involves packaging the necessary code and dependencies and making it available for use by Lambda functions. This process typically involves several key steps, each with specific considerations for optimal performance and maintainability.
- Packaging the Layer Content: The first step involves organizing the code and dependencies within a specific directory structure. This structure mirrors the expected runtime environment of the Lambda functions. Specifically, the content must be placed in a directory named `nodejs`, `python`, `java`, `dotnetcore`, `go`, `ruby`, or `provided.al2` at the root of the deployment package, depending on the Lambda function’s runtime. For instance, Python dependencies should reside within a `python/lib/python3.x/site-packages` directory structure within the layer.
- Creating the Layer Archive: The packaged content is then compressed into a ZIP archive. This archive serves as the deployment package for the Lambda layer. This archive should be created with the root directory as the starting point, preserving the internal directory structure.
- Uploading the Layer to AWS: The ZIP archive is uploaded to Amazon S3. This storage location provides the object needed to create a Lambda layer. The AWS CLI or the AWS Management Console is typically used for this upload.
- Creating the Layer Resource: A Lambda layer resource is created using the AWS Management Console, AWS CLI, or Infrastructure as Code (IaC) tools like AWS CloudFormation or Terraform. This process involves specifying the S3 bucket and object key of the ZIP archive, the compatible runtimes for the layer (e.g., Python 3.9, Node.js 16), and optionally, a description and layer name. The layer version is then created.
- Versioning the Layer: Each time the content of a layer changes, a new layer version should be created. This versioning allows for easy rollback to previous versions and supports incremental updates to Lambda functions. The layer version is assigned a unique Amazon Resource Name (ARN).
Associating Layers with Lambda Functions
Associating layers with Lambda functions enables the function to access the code and dependencies contained within the layer. This is achieved by configuring the Lambda function to use the layer’s ARN.
- Accessing the Layer ARN: Obtain the ARN of the deployed Lambda layer. This ARN is unique to the layer version and is used to identify the layer. The ARN can be found in the AWS Management Console, in the output of an AWS CLI command, or in the IaC configuration.
- Configuring the Lambda Function: Within the Lambda function’s configuration (either through the AWS Management Console, AWS CLI, or IaC), specify the layer ARNs in the `Layers` section. Multiple layer ARNs can be added, and the order in which they are added determines the precedence of the layers.
- Layer Precedence and Overriding: The order in which layers are added to the function is important. If multiple layers contain files with the same name, the layer listed first in the function’s configuration will take precedence. This mechanism allows for controlled overriding of dependencies.
Configuring Function Layer Application
Configuring the function to use the layers correctly, including understanding layer application order, is crucial for ensuring that the function can access the necessary dependencies and code.
- Runtime Environment Variables: When a Lambda function is executed, the runtime environment is configured to include the contents of the attached layers. Specifically, the contents of the layer are added to the function’s execution environment. This environment includes the paths to where the code is available for use. The `NODE_PATH` environment variable for Node.js, for example, will be modified to include the paths to the layers’ `node_modules` directories.
For Python, the `PYTHONPATH` environment variable is updated.
- Layer Application Order: The order in which layers are applied to the function influences the behavior of the code. The layers are applied in the order specified in the Lambda function’s configuration. If two layers provide the same file, the file from the layer listed first will be used. This feature is useful for overriding specific dependencies in lower-priority layers.
- Example: Consider a Lambda function that uses the `requests` library. The `requests` library can be placed in a Lambda layer. If the layer is versioned, updates to the library can be deployed to the Lambda function without modifying the function code. This results in improved manageability and version control. For instance, if the Lambda function is configured to use a layer containing the `requests` library and a second layer with a specific version of `urllib3`, the function will use the `urllib3` version in the second layer, provided the second layer is listed first.
Optimizing Package Size within Layers
Minimizing the size of deployment packages is crucial for efficient Lambda function performance and cost optimization. Smaller packages result in faster cold start times, reduced storage costs, and quicker deployment cycles. This section delves into strategies for achieving optimal layer size.
Strategies for Minimizing Dependency Size
Several techniques can be employed to reduce the size of dependencies included in Lambda layers. Careful consideration of these strategies is essential for creating lean and efficient deployment packages.
- Utilizing Native Dependencies When Possible: When available, leveraging pre-compiled, native dependencies can significantly reduce package size compared to including source code. For instance, if a specific library offers a pre-built binary for the Lambda’s execution environment (e.g., Amazon Linux 2), using that binary instead of the source code can drastically decrease the layer size. This approach bypasses the need for compilation during deployment, saving space and improving deployment speed.
- Dependency Pruning: Dependency pruning involves removing unnecessary parts of a library or its dependencies. This can be achieved by analyzing the library’s source code or using tools that identify and remove unused modules. For example, a large machine learning library might contain components that are not required by the Lambda function; removing these unused components can reduce the overall package size.
This process may involve manually removing files or using specialized tools designed for dependency analysis and pruning.
- Choosing Lightweight Alternatives: Evaluate and choose lightweight alternatives for dependencies whenever possible. Instead of using a full-featured library, opt for a smaller, more specialized library that provides the required functionality. For example, consider using a more streamlined HTTP client or a smaller JSON parsing library. The selection of these dependencies significantly impacts layer size.
- Selective Inclusion of Modules: For libraries that offer modular designs, selectively include only the necessary modules. This avoids the inclusion of entire libraries when only a small portion is required. For instance, many Python libraries allow you to import only specific functions or classes, preventing the loading of unnecessary code.
- Leveraging Bundlers and Minifiers: Use bundlers (e.g., Webpack, Parcel for JavaScript) and minifiers to reduce the size of code. These tools combine multiple files, remove whitespace and comments, and often perform other optimizations. For example, bundlers can be used to package JavaScript dependencies into a single, minified file. This process streamlines code and reduces the number of files, contributing to a smaller package size.
Methods for Removing Unnecessary Files and Code
Eliminating extraneous files and code from deployment packages is a critical step in size optimization. This involves a meticulous review of the package contents to ensure only essential components are included.
- Excluding Development Dependencies: Ensure that development-related dependencies, such as testing frameworks or build tools, are not included in the deployment package. These dependencies are only required during development and testing and should be excluded to reduce the size of the production environment. This is often managed through configuration files (e.g., `package.json` for Node.js) and deployment scripts.
- Removing Unused Code: Analyze the code to identify and remove unused code blocks, comments, and dead code. Tools like linters and code analyzers can help identify such elements. The code review process is a good practice to ensure that the code is clean and efficient.
- Excluding Documentation and Examples: Exclude documentation files, example code, and any other non-essential files that are not required for runtime execution. These files can significantly increase the package size without contributing to the functionality of the Lambda function.
- Using `.gitignore` or Similar Mechanisms: Utilize `.gitignore` (for Git-based projects) or equivalent mechanisms to prevent unnecessary files from being included in the deployment package. This ensures that build artifacts, temporary files, and other non-essential files are excluded.
- Cleaning Build Artifacts: After building or compiling the code, clean up any build artifacts or temporary files. These files can accumulate and unnecessarily increase the package size. Automated build processes should include steps to remove these files.
Comparing and Contrasting Dependency Management Approaches
Different dependency management approaches have varying impacts on package size optimization. Choosing the right approach depends on the programming language, project structure, and specific requirements.
- Direct Dependency Management: This approach involves directly including dependencies in the Lambda function’s deployment package or layer. It offers simplicity but can lead to larger package sizes if dependencies are not carefully managed. It is straightforward for small projects but becomes less manageable as the project grows.
- Package Managers (e.g., npm, pip, Maven): Package managers automate the process of downloading, installing, and managing dependencies. They simplify dependency resolution and versioning. However, they can also introduce larger package sizes due to the inclusion of unnecessary files and transitive dependencies.
- Containerization: Containerization (e.g., Docker) allows you to package the application and its dependencies in a container image. This approach offers consistent environments and can help manage dependencies effectively. However, it can result in larger deployment packages, especially for Lambda functions, due to the size of the container image.
- Layered Dependencies: Lambda layers are specifically designed for sharing dependencies across multiple Lambda functions. They reduce the size of individual deployment packages and improve code reuse. However, managing layers requires careful planning and organization to avoid dependency conflicts and bloat.
- Serverless Frameworks: Serverless frameworks (e.g., Serverless Framework, AWS SAM) often provide features to manage dependencies and deployment packages. They can automate the process of creating layers, bundling dependencies, and optimizing package sizes. Frameworks offer an integrated approach to dependency management, deployment, and infrastructure management.
Monitoring and Troubleshooting Layer Deployments
Effectively managing Lambda layers requires diligent monitoring and robust troubleshooting strategies. Deployment failures, performance bottlenecks, and unexpected behavior can arise, necessitating a systematic approach to identify and resolve issues. This section details common problems, debugging techniques, and log analysis methods to ensure the reliable operation of Lambda functions utilizing layers.
Common Issues Encountered During Layer Deployment
Several issues can impede the successful deployment and operation of Lambda layers. Understanding these potential pitfalls is crucial for proactive problem-solving.
- Incorrect Layer Structure: The directory structure within a layer must adhere to specific conventions. Incorrect placement of dependencies or libraries can lead to import errors at runtime. For instance, Python libraries must be placed in the `python/` directory within the layer’s root.
- Dependency Conflicts: Conflicts between dependencies within the layer and the Lambda function’s execution environment can occur. This often arises when the layer includes a library version incompatible with the function’s runtime.
- Permission Errors: Insufficient permissions on the layer’s S3 bucket or within the Lambda function’s execution role can prevent access to the layer’s content. The Lambda function’s execution role must have the `lambda:GetLayerVersion` permission.
- Size Limitations: While layers help manage package size, there are still limitations. The combined size of the function code and the layers cannot exceed the maximum allowed size (currently 250 MB unzipped).
- Runtime Mismatches: Layers are specific to the Lambda function’s runtime environment (e.g., Python 3.9, Node.js 16). Using a layer built for a different runtime will result in errors.
- Versioning Issues: Incorrect layer versioning or function configuration can lead to unexpected behavior. If a Lambda function is configured to use a specific layer version, changes to that layer version can cause issues.
Methods for Debugging and Troubleshooting Layer-Related Problems
A methodical approach is essential for diagnosing and resolving layer-related issues. Employing the following techniques can significantly improve the debugging process.
- Checking CloudWatch Logs: CloudWatch Logs provide invaluable insights into function execution, including error messages, stack traces, and performance metrics. Analyzing these logs is the first step in identifying the root cause of layer-related failures.
- Verifying Layer Configuration: Confirm that the Lambda function is correctly configured to use the intended layer version. Review the function’s configuration in the AWS Management Console or using the AWS CLI.
- Testing Locally: Where possible, simulate the Lambda function’s execution environment locally. This allows for debugging and dependency management before deployment. Tools like the Serverless Framework or AWS SAM can assist with local testing.
- Validating Layer Content: Ensure that the layer’s content is structured correctly and contains the expected dependencies. Download the layer’s content from S3 and inspect its contents.
- Simplifying the Function: Isolate the problem by simplifying the Lambda function. Temporarily remove layer dependencies to see if the issue is related to the layer. If the function works without the layer, reintroduce the layer dependencies incrementally to identify the problematic component.
- Reviewing IAM Permissions: Verify that the Lambda function’s execution role has the necessary permissions to access the layer and any other required resources.
Examples of Log Analysis to Diagnose Layer Deployment Failures
Log analysis is critical to understanding the nature of layer-related failures. Examining specific log entries can reveal valuable clues about the problem’s origin.
- Import Errors: If the logs contain “ModuleNotFoundError” or “ImportError” messages, it indicates that the Lambda function is unable to import a dependency from the layer. The error message usually includes the missing module name, guiding you to the specific dependency causing the issue. For example:
“errorMessage”: “Unable to import module ‘my_module’: No module named ‘my_module'”
This suggests that the layer is missing the ‘my_module’ or that it is not correctly installed.
- Permission Denied Errors: If the logs include “AccessDeniedException” or similar messages, it suggests a permission issue. Check the Lambda function’s execution role to ensure it has the necessary permissions to access the layer.
“errorMessage”: “User: arn:aws:sts::123456789012:assumed-role/my-lambda-role/my-function is not authorized to perform: lambda:GetLayerVersion on resource: arn:aws:lambda:us-east-1:123456789012:layer:my-layer:1”
This indicates that the Lambda function’s role lacks the necessary `lambda:GetLayerVersion` permission for the specified layer.
- Runtime Errors: Errors related to the runtime environment often appear in logs. These can include issues with the Python interpreter, Node.js version, or other runtime-specific configurations.
“errorMessage”: “Cannot find module ‘./my-module.node'”
This example suggests a problem with a native module that is not found within the Lambda’s execution environment. This could be because of incorrect architecture in the layer or because the layer is missing a necessary library.
- Layer Version Mismatches: When a Lambda function attempts to use a layer version that is no longer available or has been updated, it can result in unexpected behavior. Review the Lambda function’s configuration to ensure it is using the intended layer version. Log entries will often provide information on the version used.
Advanced Layer Management Techniques

Effectively managing Lambda layers goes beyond simply packaging and deploying code. Advanced techniques are crucial for maintaining a scalable, maintainable, and efficient serverless architecture, especially as the number of functions and dependencies grows. This section delves into strategies for leveraging shared resources, automating updates, and managing dependencies effectively.
Use of Shared Libraries and Frameworks Across Multiple Functions
Sharing code across multiple Lambda functions through layers promotes code reuse, reduces package sizes, and simplifies maintenance. The key lies in identifying common functionalities and packaging them appropriately for shared access.
Shared libraries and frameworks should be chosen strategically to maximize code reuse and minimize layer size. Well-known frameworks, like the AWS SDK, can be included in layers to avoid individual function package duplication.
- Identifying Common Functionality: Analyze the codebase of your Lambda functions to identify recurring tasks and dependencies. These might include:
- Data validation routines.
- Logging and monitoring utilities.
- Custom authentication or authorization logic.
- Third-party libraries like date-time manipulation libraries.
- Creating Layer Packages: Once common functionalities are identified, package them into separate layers. Ensure the structure of the layer mirrors how the code will be used by the Lambda functions. For example, if a library is intended for use in Python, it should be placed in the `/opt/python/lib/python3.x/site-packages/` directory.
- Layer Versioning and Updates: Implement a robust versioning strategy for your layers. This allows for controlled updates and rollbacks. When a layer is updated, all Lambda functions that use it should be updated to use the new version. This can be automated using CI/CD pipelines.
- Dependency Management: Use a package manager, such as `pip` for Python, to manage the dependencies within the layers. This simplifies the process of installing, updating, and managing third-party libraries.
- Best Practices:
- Avoid including unnecessary dependencies in layers to keep their size small.
- Test layers thoroughly before deploying them to production.
- Monitor the performance of functions that use layers to ensure that the shared code is not introducing any performance bottlenecks.
Design a System for Automatically Updating Layers and Functions
Automating the update process for Lambda layers and functions is essential for maintaining agility and minimizing manual intervention. This involves designing a system that can detect changes, build new versions, and deploy them with minimal downtime.
Automated updates can be achieved through a combination of CI/CD pipelines, infrastructure-as-code tools, and event-driven architectures. This reduces human error and accelerates the deployment process.
- CI/CD Pipelines: Implement CI/CD pipelines to automate the build, testing, and deployment of both layers and functions. When a change is detected in the layer code, the pipeline should:
- Build a new layer package.
- Test the new layer package.
- Create a new version of the layer.
- Update the Lambda functions that use the layer to point to the new version.
- Infrastructure as Code (IaC): Use IaC tools, such as Terraform or CloudFormation, to define and manage the infrastructure required for layers and functions. This includes defining the layer itself, the Lambda functions, and the dependencies between them. This approach ensures that infrastructure changes are version-controlled and reproducible.
- Event-Driven Architectures: Leverage event-driven architectures to trigger updates automatically. For example, when a new layer version is created, an event can be published to an SNS topic. Lambda functions that are subscribed to this topic can then be updated to use the new layer version.
- Automated Testing: Integrate automated testing into the CI/CD pipeline to ensure that changes to layers and functions do not introduce any regressions. This includes unit tests, integration tests, and end-to-end tests.
- Deployment Strategies: Implement deployment strategies, such as blue/green deployments, to minimize downtime during updates. This involves deploying the new version of the layer or function alongside the existing version and gradually shifting traffic to the new version.
Organize a Method for Managing Layer Dependencies with Tools like Terraform or CloudFormation
Managing dependencies between Lambda layers and functions is critical for maintaining a consistent and reliable deployment process. Infrastructure-as-code (IaC) tools like Terraform and CloudFormation provide a powerful mechanism for defining and managing these dependencies.
By using IaC, you can ensure that the deployment of layers and functions is repeatable, version-controlled, and easily managed. This approach improves the overall reliability and maintainability of your serverless architecture.
- Define Layer Resources: Using Terraform or CloudFormation, define the layer resources. This includes specifying the layer name, the runtime environment, and the S3 bucket where the layer package is stored.
- Define Function Resources: Define the Lambda function resources, including the function name, the runtime environment, and the layer ARNs.
- Establish Dependencies: Use the IaC tool to establish dependencies between the layers and the functions. This ensures that the layers are created before the functions that depend on them.
- In Terraform, you can use the `depends_on` attribute to specify dependencies.
- In CloudFormation, you can use the `DependsOn` attribute to specify dependencies.
- Versioning and Updates: Manage layer versions using IaC. When a layer is updated, update the IaC configuration to reflect the new version. This ensures that all dependent functions are updated to use the new layer version during the next deployment.
- Example: CloudFormation Template Snippet
A CloudFormation template might include the following to define a layer:
“`yaml
MyLayer:
Type: AWS::Lambda::LayerVersion
Properties:
CompatibleRuntimes:-python3.9
Content:
S3Bucket: !Ref S3BucketName
S3Key: my-layer.zip
LayerName: my-shared-library
“`And a Lambda function using it:
“`yaml
MyFunction:
Type: AWS::Lambda::Function
Properties:
FunctionName: myFunction
Handler: index.handler
Runtime: python3.9
Code:
ZipFile: |
import json
import my_shared_library # Import the library from the layer
def handler(event, context):
return
‘statusCode’: 200,
‘body’: json.dumps(my_shared_library.some_function(event))Layers:
-!Ref MyLayer
“`
Use Cases and Examples
Lambda layers provide significant advantages in managing dependencies and package sizes for serverless applications. This section explores various use cases where Lambda layers are particularly beneficial, showcasing the practical application of these features. We will examine how layers can streamline deployments, reduce costs, and improve overall application performance through a diverse set of examples.
Layers are instrumental in optimizing Lambda function deployments by centralizing common dependencies, reducing package sizes, and enabling efficient code reuse.
Layer Use Cases
Lambda layers demonstrate their versatility across a range of applications. Consider the following table illustrating diverse use cases:
| Application Type | Original Package Size | Dependencies Involved | Size Reduction Achieved |
|---|---|---|---|
| Image Processing | 150 MB | Pillow, NumPy, OpenCV | 80% |
| Machine Learning Inference | 200 MB | TensorFlow, NumPy, SciPy | 75% |
| API Gateway Integration | 80 MB | AWS SDK for Python, Requests | 60% |
| Data Transformation | 120 MB | Pandas, NumPy, PyArrow | 70% |
These examples highlight the potential for substantial size reduction, which translates to faster deployment times, reduced cold start latency, and lower storage costs.
Image Processing Example
Image processing functions frequently encounter large dependency sizes. Let’s illustrate a Lambda function designed for image resizing and watermarking using Python.
The original deployment package might include Pillow (for image manipulation), NumPy (for array operations), and potentially OpenCV (for advanced image processing tasks). Without layers, these dependencies, along with the application code, would comprise a large deployment package.
With layers, we can isolate the Pillow, NumPy, and OpenCV dependencies into a dedicated layer. The Lambda function’s deployment package would then only contain the application code, significantly reducing its size. This architecture promotes code reusability, as the same layer can be shared across multiple image processing functions.
The architecture of the Lambda function would consist of the following components:
1. Lambda Function: The core logic responsible for receiving image data, applying resizing and watermarking, and returning the processed image.
2. Layer 1 (Image Processing Dependencies): This layer contains Pillow, NumPy, and OpenCV libraries.
3.
Layer 2 (Shared Utility Functions – Optional): This layer might include helper functions for tasks like error handling or logging, shared across different Lambda functions.
4. Input: The function would receive image data, typically through an API Gateway trigger or an S3 event.
5. Output: The processed image would be saved to S3 or returned through an API Gateway response.
The Lambda function’s code would import the necessary libraries from the layer. For example:
“`python
from PIL import Image
import numpy as np
# Other library imports
“`
The execution flow would be:
1. The Lambda function is invoked.
2. The function’s code is executed.
3.
The libraries from the layers are loaded.
4. Image processing operations are performed.
5. The processed image is returned.
This approach reduces deployment size, enhances code reusability, and simplifies dependency management.
Ending Remarks
In conclusion, the effective management of large deployment packages in AWS Lambda hinges on a comprehensive understanding and strategic implementation of Lambda Layers. By mastering the techniques Artikeld, developers can mitigate size limitations, optimize performance, and enhance the overall efficiency of their serverless applications. This approach not only improves deployment speed but also contributes to more maintainable and scalable codebases, ultimately fostering a more robust and agile development process.
Common Queries
What is the maximum size for a Lambda Layer?
The unzipped size of a Lambda Layer, including all its contents, is limited to 250 MB. This is a critical constraint to consider when packaging dependencies and shared resources.
Can I use Lambda Layers with all Lambda runtimes?
Yes, Lambda Layers are compatible with all supported Lambda runtimes, including Node.js, Python, Java, Go, .NET, and custom runtimes. This allows for broad applicability across various projects.
How do I update a Lambda Layer?
Updating a Lambda Layer involves creating a new version of the layer with the updated code or dependencies. You then update the Lambda functions to point to the new layer version. This allows for version control and rollback capabilities.
What happens if a Lambda function uses a layer that is later deleted?
If a Lambda function is configured to use a layer that is subsequently deleted, the function will fail to execute. It is therefore essential to manage layer lifecycles carefully and ensure that layers are not deleted while they are still in use.
How does layer order affect function execution?
The order in which layers are attached to a Lambda function matters. When a function is executed, the layers are processed in the order they are attached. This means that dependencies in the first layer will be available to subsequent layers and the function code itself. Therefore, the correct order is crucial for ensuring the proper resolution of dependencies.