Post-migration optimization is a critical, yet often underestimated, phase in any cloud or infrastructure transition. It’s not merely about replicating an existing environment in a new location; it’s about reimagining it for improved performance, cost efficiency, and enhanced security. This strategy systematically addresses the changes that occur after a system has been moved from one environment to another, whether on-premise to cloud, cloud to cloud, or within the same cloud provider.
The essence of post-migration optimization lies in a proactive, iterative approach. It involves identifying and addressing performance bottlenecks, cost inefficiencies, and security vulnerabilities that may have emerged or been exacerbated during the migration process. The primary objective is to ensure the migrated environment functions optimally, leveraging the full potential of the new infrastructure while minimizing operational expenses and maintaining a robust security posture.
This requires a deep understanding of the migrated workloads, the new environment’s capabilities, and the implementation of targeted optimization techniques.
Defining Post-Migration Optimization
Post-migration optimization is a critical phase in the cloud adoption lifecycle. It follows the initial migration of workloads and data to a cloud environment and focuses on refining the deployed infrastructure for optimal performance, cost-efficiency, and security. This strategy is not a one-time event but an ongoing process of analysis, adjustment, and improvement.
Core Objective of Post-Migration Optimization
The core objective of a post-migration optimization strategy is to maximize the value derived from cloud investments. This involves achieving a balance between performance, cost, and security, ensuring that the migrated workloads operate efficiently, securely, and within the allocated budget. It’s about ensuring that the cloud environment is not just functional but also optimized for the specific needs of the business.
Defining “Post-Migration” in Cloud Computing
In the context of cloud computing, “post-migration” refers to the period immediately following the successful transfer of workloads and data from an on-premises environment or another cloud provider to a new cloud platform. This phase begins once the migration is complete and the applications are operational in the target cloud environment. It encompasses the ongoing activities aimed at refining and improving the cloud infrastructure.
Primary Goals of Post-Migration Optimization
The primary goals of a post-migration optimization strategy are multifaceted, encompassing performance, cost, and security. Each goal is interconnected, and achieving a balance between them is crucial for overall success.
- Performance Optimization: This involves ensuring that the applications and services hosted in the cloud perform optimally. Performance optimization aims to minimize latency, maximize throughput, and ensure a responsive user experience. Techniques include:
- Right-sizing resources: Adjusting the size and type of cloud resources (e.g., virtual machines, databases) to match the actual workload demands. This avoids over-provisioning, which leads to wasted resources and increased costs, or under-provisioning, which results in performance bottlenecks.
- Optimizing code and application architecture: Reviewing and refactoring the application code and architecture to improve efficiency. This can involve identifying and resolving performance bottlenecks, optimizing database queries, and leveraging caching mechanisms.
- Implementing content delivery networks (CDNs): Using CDNs to distribute content closer to users, reducing latency and improving response times, particularly for globally distributed applications.
- Cost Optimization: Cost optimization focuses on reducing cloud spending without compromising performance or security. This involves identifying and eliminating unnecessary costs, choosing the most cost-effective cloud services, and leveraging cost-saving features. Key strategies include:
- Resource utilization monitoring: Continuously monitoring resource utilization to identify underutilized resources that can be scaled down or terminated.
- Reserved instances and savings plans: Utilizing reserved instances or savings plans offered by cloud providers to obtain significant discounts on compute resources. These plans commit to a specific level of resource usage for a fixed period, resulting in lower hourly rates.
- Automated scaling: Implementing automated scaling mechanisms to automatically adjust the number of resources based on demand. This ensures that resources are available when needed and scaled down when not in use, optimizing costs.
- Cost-aware service selection: Choosing the most cost-effective cloud services for specific workloads. For example, using serverless computing for event-driven applications can be more cost-effective than running virtual machines.
- Security Optimization: Security optimization aims to enhance the security posture of the cloud environment. This involves implementing security best practices, hardening the infrastructure, and ensuring compliance with relevant regulations. Key elements include:
- Identity and access management (IAM): Implementing robust IAM controls to manage user access and permissions. This involves using least privilege principles, multi-factor authentication, and regularly reviewing access rights.
- Network security configuration: Configuring network security controls, such as firewalls, intrusion detection systems, and virtual private networks (VPNs), to protect the cloud environment from unauthorized access and threats.
- Data encryption: Encrypting data at rest and in transit to protect sensitive information. This involves using encryption keys and managing them securely.
- Regular security audits and vulnerability assessments: Conducting regular security audits and vulnerability assessments to identify and remediate security weaknesses.
Identifying Optimization Areas

Post-migration optimization is a critical phase that determines the long-term success and efficiency of a cloud or infrastructure transition. This stage involves a comprehensive evaluation of the migrated environment to identify areas where performance, cost, and security can be enhanced. This proactive approach ensures that the migrated systems operate at their optimal capacity, minimizing operational costs and maximizing the return on investment.
Common Areas Requiring Optimization
A successful migration, while achieving the initial goal of moving workloads, doesn’t automatically guarantee optimal performance or cost-effectiveness. Several areas typically require focused optimization efforts post-migration.
- Performance Tuning: This involves adjusting system configurations, such as CPU allocation, memory management, and network settings, to match the workload’s demands. It’s essential to monitor key performance indicators (KPIs) like latency, throughput, and resource utilization to identify bottlenecks and areas for improvement. For example, if a migrated database experiences increased latency, optimizing query performance, increasing the database server’s resources, or implementing caching mechanisms could be considered.
- Cost Optimization: Migrating to the cloud presents opportunities for cost reduction. However, realizing these savings requires careful resource management and optimization. This includes right-sizing instances (selecting the appropriate size based on actual resource needs), leveraging reserved instances or savings plans, and implementing auto-scaling to dynamically adjust resources based on demand. Monitoring cloud spending and identifying underutilized resources are also key components.
- Security Hardening: The migration process might introduce new security vulnerabilities. Post-migration security hardening involves implementing measures to protect the migrated environment from threats. This includes configuring firewalls, implementing access controls, encrypting data at rest and in transit, and regularly patching and updating systems. Continuous monitoring and vulnerability assessments are critical to maintain a robust security posture.
- Network Optimization: The network configuration often needs adjustments after migration. This includes optimizing network bandwidth, latency, and throughput. Implementing content delivery networks (CDNs) for geographically distributed applications can improve user experience. Optimizing network routing and security group configurations are also essential.
- Application Optimization: This involves analyzing the migrated applications for performance bottlenecks and optimizing their code and configurations. This could include optimizing database queries, caching frequently accessed data, and improving the efficiency of application code. Monitoring application performance metrics, such as response times and error rates, is crucial for identifying areas for improvement.
Performance Optimization Methods for Different Workload Types
Different workload types have unique performance characteristics and, therefore, require tailored optimization strategies. The appropriate approach depends on the specific application, its resource demands, and its architectural design.
- Compute-Intensive Workloads: These workloads, such as scientific simulations or video encoding, benefit from optimizing CPU usage and memory allocation. This involves selecting appropriate instance types with sufficient CPU cores and memory, optimizing the code for parallel processing, and implementing efficient memory management techniques. For example, a scientific simulation might benefit from running on instances with high-performance CPUs and a large amount of RAM to reduce processing time.
- Database Workloads: Database performance is heavily influenced by factors like query optimization, indexing, and storage I/O. Optimizing these aspects can significantly improve database performance. This includes analyzing and optimizing slow-running queries, creating appropriate indexes, and selecting the correct storage type (e.g., SSDs for high-performance needs). For example, a retail website’s database might experience performance gains by optimizing frequently executed product search queries.
- Web Applications: Web applications often benefit from caching, content delivery networks (CDNs), and optimized code. Implementing caching mechanisms, such as caching frequently accessed data or web pages, can reduce server load and improve response times. Using a CDN can improve the user experience for geographically distributed users by caching content closer to them. Optimizing the application code for efficiency can also improve performance.
- Batch Processing Workloads: Batch processing workloads, such as data processing pipelines, often require optimization of resource allocation and job scheduling. This involves right-sizing instances to match the workload’s resource needs, implementing efficient job scheduling mechanisms, and optimizing data transfer between processing stages. For example, a data processing pipeline might benefit from using auto-scaling to dynamically adjust the number of worker nodes based on the volume of data being processed.
Potential Cost-Saving Opportunities Post-Migration
Post-migration, numerous opportunities exist to reduce operational costs. These opportunities often stem from the flexibility and scalability offered by cloud environments.
- Right-Sizing Instances: After the migration, analyzing the actual resource utilization of instances is crucial. Often, instances are initially provisioned with more resources than needed. Right-sizing involves selecting instances with the appropriate CPU, memory, and storage based on actual resource usage. This can significantly reduce costs without impacting performance. For instance, a web server initially running on a large instance may be able to operate effectively on a smaller, less expensive instance after its resource utilization is assessed.
- Leveraging Reserved Instances or Savings Plans: Cloud providers offer significant discounts for committing to use resources for a specific period. Reserved instances and savings plans can provide substantial cost savings compared to on-demand pricing. Analyzing the workload’s predictability and committing to a specific resource usage level can lead to significant cost reductions. For example, a company that knows it will run a specific application 24/7 can save a considerable amount by purchasing reserved instances.
- Implementing Auto-Scaling: Auto-scaling automatically adjusts the number of instances based on demand, ensuring that resources are used efficiently. This prevents over-provisioning during periods of low demand and ensures sufficient resources during peak periods. This approach reduces costs by only using the necessary resources. For instance, an e-commerce website can use auto-scaling to automatically add instances during a flash sale, preventing performance degradation and ensuring a good user experience while minimizing costs during slower periods.
- Optimizing Storage Costs: Cloud storage can be expensive, and various optimization techniques can be applied. This includes using the appropriate storage tier (e.g., using cheaper storage tiers for infrequently accessed data), deleting unused data, and optimizing data compression. Regularly reviewing storage usage and identifying opportunities to reduce storage costs is essential. For example, storing infrequently accessed backups in a cold storage tier can significantly reduce storage costs.
- Identifying and Eliminating Unused Resources: After migration, it is common to find unused or underutilized resources. Regularly monitoring resource usage and identifying and deleting unused resources, such as idle virtual machines or unused storage volumes, can significantly reduce costs.
Security Hardening Procedures to Implement
Security hardening is a crucial step in post-migration optimization, safeguarding the migrated environment against potential threats. It involves a series of proactive measures to strengthen the security posture.
- Implementing Network Security Groups/Firewalls: Configuring network security groups or firewalls is a fundamental step in securing the migrated environment. This involves defining rules to control inbound and outbound network traffic, allowing only necessary traffic to reach the instances. This limits the attack surface and prevents unauthorized access. For example, only allowing SSH access from a specific IP range can prevent unauthorized access to the instances.
- Enabling Multi-Factor Authentication (MFA): MFA adds an extra layer of security by requiring users to provide multiple forms of authentication. This helps prevent unauthorized access, even if the user’s password is compromised. Implementing MFA for all user accounts, especially those with administrative privileges, is a critical security practice.
- Encrypting Data at Rest and in Transit: Encrypting data both at rest and in transit protects sensitive information from unauthorized access. Encryption at rest ensures that data stored on storage devices is protected, while encryption in transit secures data as it moves between systems. Using encryption protocols like TLS/SSL for communication and encrypting storage volumes are essential.
- Regularly Patching and Updating Systems: Keeping systems and applications up-to-date with the latest security patches is crucial for mitigating vulnerabilities. Regularly patching operating systems, applications, and libraries prevents attackers from exploiting known vulnerabilities. Automating the patching process and establishing a clear patching schedule are important.
- Implementing Access Controls and Least Privilege: Implementing strict access controls and the principle of least privilege ensures that users only have the necessary access to perform their tasks. This minimizes the potential damage from compromised accounts. Regularly reviewing and updating access controls is essential.
- Conducting Regular Security Audits and Vulnerability Assessments: Regular security audits and vulnerability assessments identify potential security weaknesses in the environment. These assessments should include penetration testing and vulnerability scanning to identify and address security vulnerabilities.
Performance Tuning Strategies
Following a successful migration, optimizing performance is paramount to ensure applications function efficiently and provide a positive user experience. This involves a multifaceted approach, encompassing application code, database systems, network infrastructure, and comprehensive monitoring. The strategies discussed aim to proactively identify and mitigate performance bottlenecks, ultimately leading to improved responsiveness, reduced resource consumption, and enhanced overall system stability.
Techniques to Enhance Application Performance
Application performance tuning focuses on improving the efficiency of the code and its interaction with underlying resources. Several techniques can be employed to achieve significant performance gains.
- Code Profiling and Optimization: Profiling tools analyze application code to identify performance bottlenecks, such as slow function calls, inefficient loops, and memory leaks. Optimization involves rewriting code to improve its efficiency. For example, using more efficient algorithms, reducing unnecessary database queries, and optimizing data structures can dramatically improve execution speed. Consider the case of an e-commerce website. Profiling might reveal that a particular function responsible for calculating shipping costs is slow.
Optimization could involve caching frequently accessed shipping rates or pre-calculating rates for common scenarios.
- Caching Strategies: Caching involves storing frequently accessed data in a faster storage medium, such as in-memory caches (e.g., Redis, Memcached) or on the client-side (browser caching). This reduces the need to repeatedly retrieve data from slower sources like databases or remote servers. For instance, a social media platform might cache user profile information, frequently accessed posts, and friend lists. This significantly reduces the load on the database and improves page load times.
- Asynchronous Processing: Offloading time-consuming tasks to background processes (e.g., message queues like RabbitMQ or Kafka) allows the application to remain responsive to user requests. This is particularly useful for tasks like sending emails, processing large files, or performing complex calculations. An example is an online video platform. Instead of blocking the user while encoding a video, the encoding process can be queued and handled asynchronously.
The user can then continue browsing while the video is being processed in the background.
- Load Balancing: Distributing traffic across multiple servers ensures that no single server is overloaded, improving overall application performance and availability. Load balancers distribute incoming requests based on various criteria, such as server capacity, response time, or round-robin. Consider a web application with high traffic. A load balancer can distribute user requests across multiple web servers, ensuring that the application remains responsive even during peak load.
- Code Minification and Bundling: Reducing the size of JavaScript, CSS, and HTML files improves page load times. Minification removes unnecessary characters (e.g., whitespace, comments) from the code, while bundling combines multiple files into a single file. This reduces the number of HTTP requests the browser needs to make.
Database Optimization Strategies
Database optimization is crucial for ensuring efficient data retrieval and storage, directly impacting application performance. Various strategies can be employed to optimize database performance.
- Indexing: Creating indexes on frequently queried columns significantly speeds up data retrieval by allowing the database to quickly locate the relevant data. However, excessive indexing can slow down write operations. The choice of indexes should be carefully considered based on the query patterns. For example, in an e-commerce database, creating indexes on the `product_id` and `category_id` columns can significantly speed up product searches.
- Query Optimization: Analyzing and optimizing SQL queries can improve their execution time. This involves rewriting inefficient queries, using appropriate join strategies, and ensuring that queries are using indexes effectively. Database query analyzers provide valuable insights into query performance. For example, a poorly written query that retrieves all columns from a table when only a few are needed can be optimized by specifying only the required columns in the `SELECT` statement.
- Database Caching: Caching frequently accessed data within the database server itself can reduce the load on the underlying storage and improve query performance. This is often implemented through techniques like query result caching.
- Database Schema Optimization: Designing an efficient database schema is crucial for performance. This involves normalizing the database to reduce data redundancy, using appropriate data types, and avoiding unnecessary columns. Consider a database storing customer orders. Properly normalizing the schema can prevent data inconsistencies and improve query performance.
- Connection Pooling: Using connection pooling reduces the overhead of establishing and closing database connections, which can be a significant bottleneck for applications with high database interaction. Connection pooling allows applications to reuse existing database connections, minimizing the time spent establishing new connections.
Methods for Optimizing Network Configuration
Network configuration plays a vital role in application performance, especially in distributed systems. Several methods can be used to optimize the network.
- Bandwidth Optimization: Ensuring sufficient bandwidth between servers and clients is crucial. This involves selecting appropriate network interfaces, optimizing network configurations, and potentially upgrading network infrastructure if necessary. Consider an application hosted on a cloud platform. Optimizing network bandwidth can prevent delays when transferring large files or processing data.
- Latency Reduction: Minimizing network latency is essential for improving application responsiveness. This involves strategies like choosing geographically closer servers, optimizing DNS resolution, and using content delivery networks (CDNs) to cache content closer to users.
- Network Protocol Optimization: Choosing the right network protocols and optimizing their configurations can improve performance. For example, using HTTP/2 or HTTP/3 can improve web application performance by enabling features like multiplexing and header compression.
- TCP/IP Tuning: Fine-tuning TCP/IP settings, such as the TCP window size and maximum segment size (MSS), can improve network throughput and reduce latency. These settings should be adjusted based on the specific network environment and application requirements.
- Firewall Optimization: Properly configuring firewalls to allow only necessary traffic can improve network security and reduce latency. Overly restrictive or poorly configured firewalls can introduce delays in network communication.
Design a Strategy for Monitoring and Alerting on Performance Metrics
A robust monitoring and alerting strategy is crucial for proactively identifying and addressing performance issues. The strategy should encompass the following elements.
- Metric Selection and Collection: Define a comprehensive set of performance metrics to monitor. These metrics should cover all critical aspects of the application and infrastructure, including CPU utilization, memory usage, disk I/O, network traffic, database query performance, and application response times. Choose appropriate monitoring tools (e.g., Prometheus, Grafana, Datadog, New Relic) to collect these metrics.
- Threshold Definition: Establish clear thresholds for each metric to define acceptable performance levels. These thresholds should be based on historical data, performance benchmarks, and service level agreements (SLAs).
- Alerting Configuration: Configure alerts to trigger when performance metrics exceed predefined thresholds. Alerts should be sent to relevant stakeholders (e.g., developers, operations teams) through appropriate channels (e.g., email, SMS, Slack).
- Dashboarding and Visualization: Create dashboards to visualize performance metrics in real-time. Dashboards should provide a clear and concise overview of the application’s performance, allowing for quick identification of issues.
- Automated Reporting: Implement automated reporting to regularly summarize performance metrics and identify trends. This can help in proactively addressing potential performance bottlenecks.
- Incident Response Plan: Develop a detailed incident response plan that Artikels the steps to be taken when performance issues are detected. This plan should include procedures for troubleshooting, remediation, and communication.
Cost Management and Optimization
Post-migration, effectively managing and optimizing cloud costs is paramount to realizing the full benefits of cloud adoption. Without diligent cost control, the anticipated financial advantages of migrating to the cloud can be quickly eroded. This section focuses on strategies and techniques to minimize cloud spending, ensuring cost-effectiveness and maximizing return on investment.
Organizing Cost Optimization Techniques for Cloud Resources
Cost optimization in the cloud is not a one-time activity, but an ongoing process that requires a multi-faceted approach. Effective cost management requires a structured and systematic methodology.
- Resource Right-Sizing: This involves matching the resources allocated to workloads with their actual needs. Underutilized resources are identified and scaled down, while over-utilized resources are scaled up. This process often leverages monitoring tools to track resource utilization metrics like CPU, memory, and network I/O.
- Instance Selection: Choosing the appropriate instance type for each workload is crucial. This includes considering factors such as CPU cores, memory, storage, and network bandwidth. Instance families are often categorized by use case, such as compute-optimized, memory-optimized, and storage-optimized.
- Automated Scaling: Implementing auto-scaling policies allows resources to be automatically adjusted based on demand. This helps to optimize costs by scaling up resources during peak periods and scaling down during off-peak periods. Auto-scaling can be triggered by metrics such as CPU utilization, request queue length, or custom metrics.
- Storage Optimization: Selecting the appropriate storage tier based on data access frequency and performance requirements is important. For example, infrequently accessed data can be stored in lower-cost tiers like cold storage. Data lifecycle management policies can be implemented to automatically move data between different storage tiers.
- Cost Allocation and Tagging: Implementing a robust tagging strategy enables cost allocation across different departments, projects, or applications. This allows for granular cost analysis and identification of areas where costs can be reduced. Tags should be consistently applied to all cloud resources.
- Cost Monitoring and Analysis: Regularly monitoring cloud spending and analyzing cost trends is essential. Cloud providers offer cost management tools that provide detailed reports and visualizations. Cost anomaly detection tools can be used to identify unexpected cost increases.
- Reserved Instances and Savings Plans: Utilizing reserved instances or savings plans can significantly reduce costs by committing to a specific level of resource usage over a period of time. The discount offered varies depending on the term and payment options.
- Third-Party Cost Management Tools: Leveraging third-party cost management tools can provide additional features and insights, such as advanced cost optimization recommendations, budget alerts, and automated reporting.
Creating a Plan for Right-Sizing Cloud Instances
Right-sizing cloud instances is a critical step in optimizing cloud costs. The process involves analyzing resource utilization and adjusting instance sizes to match the actual needs of the workloads. A well-defined plan is essential to ensure that resources are neither under-provisioned (leading to performance issues) nor over-provisioned (leading to unnecessary costs).
- Establish Baseline Metrics: Gather historical data on resource utilization for each workload. This data should include metrics such as CPU utilization, memory usage, network I/O, and disk I/O. Use monitoring tools provided by the cloud provider or third-party monitoring solutions to collect this data.
- Analyze Resource Utilization: Analyze the collected data to identify instances that are consistently underutilized or overutilized. Look for patterns and trends in resource usage. Consider factors such as seasonal variations in demand.
- Identify Optimization Opportunities: Based on the analysis, identify instances that can be right-sized. This may involve scaling down instances that are underutilized or scaling up instances that are overutilized.
- Test and Validate Changes: Before making changes to instance sizes, test the impact on performance. This can be done by running performance tests or by monitoring the performance of the workload after the changes are made.
- Implement Changes: Implement the right-sizing changes in a phased approach. Start with a small number of instances and monitor the results before making changes to a larger number of instances. Use automation tools to streamline the process.
- Monitor and Refine: Continuously monitor resource utilization and refine the right-sizing plan as needed. Resource requirements may change over time, so it’s important to regularly review and adjust instance sizes.
For example, consider a web application running on an EC2 instance. Monitoring reveals that the CPU utilization rarely exceeds 20% during peak hours. In this case, the instance could be downsized to a smaller instance type, potentially saving costs without impacting performance. Conversely, if a database server consistently experiences high CPU utilization and slow query response times, the instance may need to be upsized to improve performance.
Demonstrating How to Leverage Reserved Instances or Savings Plans
Reserved instances and savings plans are cost-saving options offered by cloud providers that provide significant discounts on compute resources in exchange for a commitment to a specific level of usage. These options are particularly beneficial for workloads with predictable resource requirements. The choice between reserved instances and savings plans depends on the specific needs and usage patterns of the cloud environment.
- Reserved Instances: Reserved instances offer significant discounts compared to on-demand pricing. The discount is typically applied to the hourly usage of the instance. The level of discount varies depending on the instance type, region, and commitment term (e.g., 1-year or 3-year). There are also different payment options available, such as all upfront, partial upfront, and no upfront. Reserved instances are best suited for workloads with predictable resource requirements and long-term commitments.
- Savings Plans: Savings plans offer flexible pricing models that provide discounts on compute usage in exchange for a commitment to a consistent amount of spending over a specific period (e.g., 1-year or 3-year). Unlike reserved instances, savings plans are not tied to specific instance types or regions, offering greater flexibility. There are two main types of savings plans: compute savings plans and EC2 instance savings plans.
Compute savings plans apply to a broader range of compute usage, including EC2 instances, Fargate, and Lambda. EC2 instance savings plans apply specifically to EC2 instances. Savings plans are well-suited for workloads with variable resource needs and a commitment to spend a certain amount over a period of time.
- Determining the Right Approach: To determine the most appropriate option, analyze the resource usage patterns and forecast future needs. For workloads with consistent usage, reserved instances may offer the best cost savings. For workloads with fluctuating usage, savings plans may provide greater flexibility.
- Implementation Steps:
- Analyze Usage: Use cloud provider tools or third-party solutions to analyze current and historical usage patterns.
- Calculate Savings: Utilize cost calculators to estimate the potential savings from reserved instances or savings plans.
- Purchase Commitment: Purchase the appropriate reserved instances or savings plans based on the analysis.
- Monitor and Optimize: Regularly monitor usage and adjust the commitment as needed to maximize savings.
For instance, a company running a database server continuously for 24/7 can significantly reduce costs by purchasing a 3-year reserved instance for the specific instance type and region. This commitment ensures a consistent discount on the instance’s hourly usage. Alternatively, a company with fluctuating workloads can benefit from a compute savings plan by committing to a certain amount of spending on compute resources, allowing flexibility in instance selection and usage.
Providing Methods to Automate Cost Monitoring and Reporting
Automating cost monitoring and reporting is crucial for maintaining visibility into cloud spending and identifying cost optimization opportunities. Manual cost tracking is time-consuming and prone to errors. Automated solutions provide real-time insights, enabling proactive cost management and informed decision-making.
- Utilizing Cloud Provider Tools: Cloud providers offer native cost management tools that provide dashboards, reports, and alerts. These tools can be used to track spending, set budgets, and receive notifications when spending exceeds thresholds. For example, AWS Cost Explorer, Azure Cost Management + Billing, and Google Cloud Billing provide detailed cost analysis and reporting capabilities.
- Implementing Cost Allocation Tags: As previously discussed, tagging resources allows for granular cost allocation. Automating the application of tags to all new resources ensures accurate cost tracking and reporting. This can be achieved through infrastructure-as-code tools or automated scripts.
- Setting up Budget Alerts: Configure budget alerts to receive notifications when spending approaches or exceeds predefined thresholds. This helps to prevent unexpected cost overruns. Budget alerts can be customized to trigger notifications via email, SMS, or other channels.
- Automating Reporting: Automate the generation of cost reports to provide regular insights into spending trends. This can be achieved using cloud provider APIs, third-party cost management tools, or custom scripts. Reports can be generated on a daily, weekly, or monthly basis and delivered via email or other channels.
- Leveraging Third-Party Tools: Third-party cost management tools often provide advanced automation features, such as anomaly detection, cost optimization recommendations, and automated remediation actions. These tools can integrate with cloud provider APIs to collect cost data, generate reports, and trigger alerts.
- Creating Custom Scripts: For specific requirements, custom scripts can be developed to automate cost monitoring and reporting. These scripts can use cloud provider APIs to collect data, perform calculations, and generate reports. This approach provides greater flexibility and control over the reporting process.
For example, a company can use AWS Cost Explorer to create a daily report that tracks spending by department. The report can be automatically generated and emailed to the respective department heads. Additionally, they can set up budget alerts to notify the finance team if spending exceeds a certain threshold. This proactive approach ensures that any cost anomalies are quickly identified and addressed.
Another example is the utilization of a third-party tool that automatically detects cost anomalies and provides recommendations for optimization, such as right-sizing instances or deleting unused resources.
Security Hardening and Compliance

Post-migration, the security posture of the migrated environment requires immediate and rigorous attention. This phase focuses on implementing robust security measures to protect data and applications, as well as establishing a framework to maintain compliance with relevant regulations. A proactive approach, encompassing best practices, regular assessments, and continuous monitoring, is essential to mitigate risks and ensure the integrity of the migrated system.
Security Best Practices Post-Migration
Following a successful migration, several security best practices should be immediately implemented to establish a secure foundation. These practices aim to minimize vulnerabilities and protect against potential threats.
- Implement Least Privilege Access: Grant users and applications only the minimum necessary permissions required to perform their tasks. This principle limits the potential damage from a compromised account. For example, database administrators should not automatically have root access to the operating system.
- Regularly Patch and Update Systems: Establish a consistent patching schedule for all operating systems, applications, and security software. Timely patching addresses known vulnerabilities, reducing the attack surface. Automated patching systems can streamline this process.
- Enable Multi-Factor Authentication (MFA): Implement MFA for all user accounts, especially those with administrative privileges. MFA significantly enhances security by requiring users to verify their identity using multiple factors, such as a password and a one-time code from a mobile device.
- Monitor and Audit Activity: Implement comprehensive logging and monitoring solutions to track user activity, system events, and security incidents. Regularly review logs to detect suspicious behavior and potential security breaches. Security Information and Event Management (SIEM) systems can automate log analysis and threat detection.
- Encrypt Data at Rest and in Transit: Encrypt sensitive data stored on disks and transmitted over networks. Encryption protects data from unauthorized access, even if the storage media or network traffic is compromised. This includes database encryption, file encryption, and secure communication protocols like HTTPS.
- Implement Network Segmentation: Segment the network into logical zones to isolate critical assets and limit the impact of a security breach. This can involve using firewalls, virtual private networks (VPNs), and other network security devices to control traffic flow between different segments.
- Conduct Security Awareness Training: Educate users about security threats, such as phishing, social engineering, and malware. Regular training helps users identify and avoid security risks, reducing the likelihood of successful attacks.
- Secure Configuration Management: Implement and maintain secure configurations for all systems and applications. This includes disabling unnecessary services, configuring security settings, and hardening the operating system. Configuration management tools can automate and enforce these settings.
Implementing Access Controls and IAM Policies
Effective access control is crucial for protecting sensitive data and resources. Implementing robust Identity and Access Management (IAM) policies ensures that only authorized users and applications can access specific resources.
- Define Roles and Responsibilities: Clearly define roles and responsibilities within the organization, specifying the access rights associated with each role. This helps to streamline access control and ensure that users have only the necessary permissions.
- Implement Role-Based Access Control (RBAC): Utilize RBAC to assign permissions to roles rather than individual users. This simplifies access management and allows for easy modification of permissions when roles change.
- Use IAM Services (e.g., AWS IAM, Azure IAM, Google Cloud IAM): Leverage the IAM services provided by cloud providers to manage users, groups, and permissions. These services offer features such as multi-factor authentication, access key rotation, and policy-based access control.
- Create and Enforce IAM Policies: Develop detailed IAM policies that define the specific actions users and applications are allowed to perform on resources. Regularly review and update these policies to reflect changes in the environment and security requirements.
- Example: AWS IAM Policy: Consider a scenario where a user needs read-only access to a specific S3 bucket. The following IAM policy grants this access:
"Version": "2012-10-17", "Statement": [ "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::your-bucket-name", "arn:aws:s3:::your-bucket-name/*" ] ]
This policy allows the user to get objects and list the contents of the specified S3 bucket.
- Regularly Review Access Permissions: Conduct periodic reviews of user access permissions to ensure that they are still appropriate. Remove or modify permissions as needed to maintain a least-privilege access model.
Procedures for Vulnerability Scanning and Penetration Testing
Regular vulnerability scanning and penetration testing are critical components of a proactive security strategy. These activities help identify and address security weaknesses before they can be exploited by attackers.
- Vulnerability Scanning: Utilize automated vulnerability scanners to identify known vulnerabilities in systems and applications. These scanners assess the environment for security flaws, misconfigurations, and outdated software.
- Frequency: Perform vulnerability scans on a regular schedule, such as weekly or monthly, and after any significant system changes or software updates.
- Tools: Popular vulnerability scanning tools include OpenVAS, Nessus, and Qualys.
- Penetration Testing: Conduct penetration tests to simulate real-world attacks and assess the effectiveness of security controls. Penetration testers attempt to exploit vulnerabilities to gain unauthorized access to systems and data.
- Scope: Define the scope of the penetration test, including the systems and applications to be tested and the attack vectors to be used.
- Frequency: Perform penetration tests at least annually, or more frequently if there are significant changes to the environment or security requirements.
- Reporting: Generate detailed reports that document the findings of the vulnerability scans and penetration tests, including identified vulnerabilities, their severity, and recommendations for remediation.
- Remediation: Prioritize and address the identified vulnerabilities based on their severity and potential impact. Implement the recommended remediation steps, such as patching systems, configuring security settings, and updating software.
Strategy for Achieving and Maintaining Compliance
Achieving and maintaining compliance with relevant regulations and industry standards is essential for protecting sensitive data and avoiding penalties. A well-defined compliance strategy includes several key elements.
- Identify Applicable Regulations and Standards: Determine the specific regulations and industry standards that apply to the migrated environment. This may include regulations such as GDPR, HIPAA, PCI DSS, and industry standards such as ISO 27001.
- Conduct a Gap Analysis: Assess the current security posture against the requirements of the identified regulations and standards. Identify any gaps or deficiencies in the existing security controls.
- Develop a Compliance Plan: Create a detailed plan to address the identified gaps and achieve compliance. This plan should include specific tasks, timelines, and responsible parties.
- Implement Security Controls: Implement the necessary security controls to meet the requirements of the regulations and standards. This may include implementing access controls, encrypting data, and implementing security monitoring.
- Document Procedures and Policies: Document all security procedures and policies to demonstrate compliance. This documentation should include details about security controls, incident response plans, and data protection measures.
- Train Personnel: Provide training to personnel on the requirements of the regulations and standards, as well as the security controls that have been implemented.
- Conduct Regular Audits: Perform regular internal and external audits to assess the effectiveness of security controls and ensure ongoing compliance.
- Maintain and Update Compliance Posture: Continuously monitor and update the compliance posture to reflect changes in the environment, regulations, and industry standards. This includes regularly reviewing and updating security controls, policies, and procedures.
- Example: PCI DSS Compliance: For organizations that handle credit card data, achieving PCI DSS compliance is crucial. This involves implementing a comprehensive set of security controls, including:
- Maintaining a firewall to protect cardholder data.
- Encrypting transmission of cardholder data across open, public networks.
- Regularly testing security systems and processes.
- Restricting physical access to cardholder data.
Failure to comply with PCI DSS can result in significant fines and reputational damage.
Data Optimization and Management
Post-migration data optimization is crucial for maximizing the value of migrated data assets and ensuring their long-term usability, accessibility, and cost-effectiveness. This involves a multifaceted approach encompassing storage optimization, archiving strategies, data lifecycle management, robust backup and disaster recovery plans, and adherence to data governance policies. Effective data management is essential for maintaining data integrity, supporting business intelligence initiatives, and complying with regulatory requirements.
Techniques for Data Storage Optimization
Data storage optimization focuses on minimizing storage costs, improving performance, and enhancing data accessibility. This is achieved through various techniques that efficiently manage data volume and structure.
- Data Compression: Employing compression algorithms, such as LZ77 or DEFLATE, to reduce the physical storage footprint of data. This is particularly effective for text-based data, logs, and backups. Compression can be implemented at the file system level, within database systems, or at the storage array level. The degree of compression achieved depends on the data type and the compression algorithm used.
For example, a study by the University of California, Berkeley, demonstrated up to 80% compression ratios for certain text and log data using advanced compression techniques.
- Data Deduplication: Identifying and eliminating redundant data blocks, storing only unique data instances. This is particularly beneficial for virtual machine images, backups, and large datasets with repetitive content. Deduplication can be performed at the source (client-side), target (server-side), or inline (during data ingestion). According to a report by the Enterprise Strategy Group, data deduplication can reduce storage capacity requirements by 50-90% in many environments.
- Data Tiering: Moving data between different storage tiers based on access frequency and performance requirements. Frequently accessed “hot” data resides on high-performance storage (e.g., SSDs), while less frequently accessed “cold” data is moved to lower-cost storage (e.g., HDDs or cloud object storage). This strategy optimizes performance and cost. For instance, a financial institution might tier its transaction data, placing recent transactions on SSDs for quick access and older, less frequently accessed transactions on slower, cheaper storage.
- Data Indexing: Creating indexes to speed up data retrieval by providing a structured way to locate specific data points within larger datasets. This is critical for database performance and search efficiency. Indexing can be applied to various data types, including relational databases, NoSQL databases, and file systems. Properly designed indexes can significantly reduce query response times, often by orders of magnitude.
- Data Partitioning: Dividing large datasets into smaller, more manageable partitions based on logical criteria (e.g., time, geography, customer segment). This improves query performance and simplifies data management tasks. Partitioning can be implemented at the database level or within data processing frameworks. For example, a retail company could partition its sales data by month or region to improve query performance for sales analysis.
Methods for Data Archiving and Lifecycle Management
Data archiving and lifecycle management ensure that data is retained for its required duration, while also optimizing storage costs and compliance with regulations. These methods involve policies and technologies to manage data from creation to disposal.
- Data Archiving: Moving inactive data to a separate, lower-cost storage tier for long-term retention. Archived data is typically accessed less frequently but must be available when needed. Archiving often involves migrating data to tape storage, cloud object storage, or specialized archive systems. The key is to ensure data integrity and accessibility for the archive’s lifetime.
- Data Retention Policies: Establishing and enforcing policies that define how long data must be retained, based on business requirements, legal obligations, and regulatory mandates. These policies should specify data types, retention periods, and disposal procedures. For example, financial institutions are often required to retain financial records for a minimum of seven years.
- Data Lifecycle Automation: Automating the movement of data through different stages of its lifecycle, from active to inactive to archive to deletion. This includes using automated tools to identify data eligible for archiving, move it to the appropriate storage tier, and manage its retention. This automation streamlines the data management process and reduces manual effort.
- Data Governance: Implementing data governance frameworks that define data ownership, data quality standards, data access controls, and data security policies. Data governance ensures data is managed consistently and in compliance with relevant regulations. This includes defining roles and responsibilities for data management and establishing procedures for data quality monitoring and remediation.
- Data Deletion/Purging: Securely deleting data when its retention period expires or when it is no longer needed. This includes using secure deletion methods to prevent data recovery and ensure compliance with privacy regulations. Proper data deletion is crucial to minimize security risks and reduce storage costs.
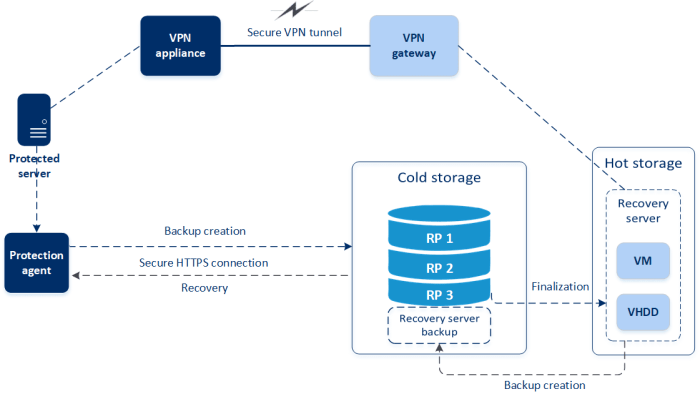
Strategies for Data Backup and Disaster Recovery
Data backup and disaster recovery (DR) strategies are essential for protecting data against data loss, system failures, and natural disasters. These strategies ensure business continuity and data availability.
- Backup Types:
- Full Backup: A complete copy of all data. It’s the simplest but most time-consuming backup type.
- Incremental Backup: Backs up only the data that has changed since the last backup (full or incremental). This is faster but requires a chain of backups for restoration.
- Differential Backup: Backs up data that has changed since the last full backup. This is faster than incremental backups for restoring but slower than incremental for backups.
- Backup Frequency: Determining the frequency of backups based on the Recovery Point Objective (RPO) and Recovery Time Objective (RTO). RPO defines the maximum acceptable data loss, while RTO defines the maximum acceptable downtime. Frequent backups minimize data loss, but increase storage costs and backup time.
- Backup Location: Storing backups in geographically diverse locations to protect against site-specific disasters. This includes on-site backups for fast recovery and off-site backups for disaster recovery. Considerations include using cloud-based backup services, which offer scalability and cost-effectiveness.
- Disaster Recovery Planning: Developing a comprehensive DR plan that Artikels procedures for restoring data and systems in the event of a disaster. This includes identifying critical systems, defining recovery procedures, and testing the plan regularly. The DR plan should address failover, failback, and data restoration processes.
- Data Replication: Creating real-time or near-real-time copies of data on separate storage systems. This enables rapid failover to a secondary site in case of a primary site failure. Data replication can be synchronous (guaranteed data consistency) or asynchronous (faster replication with potential data loss).
Data Storage Options and Their Characteristics
The selection of data storage options should be based on factors such as performance requirements, cost considerations, data volume, and access frequency.
| Storage Option | Characteristics | Use Cases |
|---|---|---|
| Solid State Drives (SSDs) | High performance, fast read/write speeds, expensive per GB, limited lifespan (write cycles). | Operating systems, databases, applications requiring high I/O performance, caching. |
| Hard Disk Drives (HDDs) | Lower cost per GB, slower read/write speeds, higher capacity, longer lifespan. | Bulk storage, data archiving, backups, less frequently accessed data. |
| Cloud Object Storage | Scalable, cost-effective, highly durable, accessible via API, pay-as-you-go pricing. | Data archiving, backups, media storage, content delivery, big data analytics. Examples include Amazon S3, Azure Blob Storage, Google Cloud Storage. |
| Network Attached Storage (NAS) | File-level storage, easy to set up and manage, shared access, suitable for small to medium-sized businesses. | File sharing, collaboration, backups, media storage. |
| Storage Area Network (SAN) | Block-level storage, high performance, centralized storage management, suitable for enterprise environments. | Databases, virtual machines, applications requiring high I/O performance. |
| Tape Storage | Very low cost per GB, high capacity, slow access speeds, suitable for long-term archiving and disaster recovery. | Data archiving, long-term backups, offsite storage. |
Application Optimization and Refactoring

Post-migration application optimization is a critical phase that focuses on refining applications to leverage the benefits of the cloud environment. This process goes beyond simply moving applications; it involves strategic adjustments to improve performance, reduce costs, enhance security, and increase overall efficiency. Application optimization and refactoring strategies are crucial to fully realizing the potential of cloud migration and ensuring long-term success.
Application Refactoring Strategies for Cloud Environments
Refactoring applications for cloud environments involves modifying the existing codebase to improve its structure, design, and implementation. This process aims to enhance performance, scalability, maintainability, and cost-effectiveness within the cloud infrastructure. Several refactoring strategies are available, each with its specific applications and benefits.
- Lift and Shift (Rehosting): This strategy involves migrating the application to the cloud with minimal changes to the application’s code. The application is typically re-hosted on virtual machines (VMs) in the cloud. While it is the simplest approach, it often doesn’t fully leverage the cloud’s capabilities and may not lead to significant performance improvements or cost savings. The main advantage is the speed of migration.
- Replatforming: Replatforming involves making some changes to the application to take advantage of cloud-native features, such as managed databases or load balancers. The core application logic remains largely unchanged, but the infrastructure is optimized for the cloud. This strategy can improve performance and reduce operational overhead.
- Refactoring (Rearchitecting): This is a more involved process where the application’s architecture is significantly altered to align with cloud-native principles. This may involve breaking down a monolithic application into microservices, adopting serverless computing, or leveraging containerization. Refactoring offers the most potential for optimization but requires more time and resources. This approach often yields significant improvements in scalability, resilience, and cost efficiency.
- Re-architecting (Rebuilding): This is the most comprehensive approach, where the application is completely rebuilt using cloud-native technologies. This strategy allows for the creation of a highly optimized and scalable application that fully leverages the cloud’s capabilities. It is often the most expensive and time-consuming option, but it can deliver the greatest benefits in terms of performance, scalability, and cost optimization.
Comparison of Different Application Deployment Models
The choice of deployment model significantly impacts application performance, scalability, and cost. Different models offer varying levels of control, automation, and resource utilization. The selection should be based on the application’s specific requirements and the organization’s capabilities.
- Virtual Machines (VMs): VMs provide a high degree of control over the underlying infrastructure. They are suitable for applications that require specific operating systems, software configurations, or have dependencies that are difficult to manage in other models. VMs offer a familiar environment for many applications but can be less efficient in terms of resource utilization compared to containerization or serverless.
- Containerization (e.g., Docker, Kubernetes): Containerization packages applications and their dependencies into isolated units called containers. Containers are lightweight, portable, and can be easily deployed across different environments. Containerization promotes efficient resource utilization and simplifies application deployment and management. Kubernetes is a popular container orchestration platform that automates the deployment, scaling, and management of containerized applications.
- Serverless Computing (e.g., AWS Lambda, Azure Functions, Google Cloud Functions): Serverless computing allows developers to run code without managing servers. The cloud provider automatically provisions and manages the necessary infrastructure. Serverless is ideal for event-driven applications, microservices, and tasks that can be broken down into small, independent functions. Serverless offers high scalability, pay-per-use pricing, and reduces operational overhead.
Methods for Improving Application Scalability and Availability
Scalability and availability are crucial for ensuring that applications can handle increasing workloads and remain accessible to users. Several techniques can be employed to enhance these aspects.
- Horizontal Scaling: This involves adding more instances of the application to handle increased traffic. Load balancers distribute traffic across multiple instances, ensuring high availability and preventing any single instance from becoming a bottleneck. This is a common and effective strategy for scaling web applications.
- Vertical Scaling: Vertical scaling involves increasing the resources (e.g., CPU, memory) of a single application instance. While it can improve performance, it has limitations, as there is a physical limit to the resources a single instance can have.
- Auto-scaling: Auto-scaling automatically adjusts the number of application instances based on real-time demand. Cloud providers offer auto-scaling services that monitor resource utilization and automatically scale the application up or down. This ensures that applications can handle peak loads and minimize costs during periods of low activity.
- Caching: Caching stores frequently accessed data in memory or on a content delivery network (CDN). Caching reduces the load on backend systems, improves response times, and enhances scalability. Caching strategies can be implemented at various levels, including the application layer, database layer, and network layer.
- Database Optimization: Optimizing database performance is critical for application scalability. Techniques include query optimization, indexing, and database sharding. Sharding distributes data across multiple database instances, enabling horizontal scaling of the database.
- Redundancy and Failover: Implementing redundancy and failover mechanisms ensures that applications remain available even if some components fail. This can involve using multiple application instances, redundant databases, and automatic failover processes.
Demonstrating How to Monitor and Optimize Application Performance
Monitoring and optimizing application performance is an iterative process that involves continuous analysis and refinement. It requires the use of monitoring tools, performance metrics, and optimization strategies.
- Performance Monitoring Tools: Performance monitoring tools collect data on application performance metrics, such as response times, error rates, and resource utilization. These tools provide real-time insights into application behavior and help identify performance bottlenecks. Examples include Prometheus, Grafana, Datadog, and New Relic.
- Key Performance Indicators (KPIs): KPIs are specific metrics that are used to measure application performance. Common KPIs include:
- Response Time: The time it takes for an application to respond to a user request.
- Error Rate: The percentage of requests that result in errors.
- Throughput: The number of requests processed per unit of time.
- Resource Utilization: The amount of CPU, memory, and storage used by the application.
- Performance Analysis: Analyzing performance data to identify bottlenecks and areas for improvement. This may involve profiling the application code to identify slow-running functions, analyzing database queries, and monitoring network traffic.
- Optimization Strategies: Implementing optimization strategies to address identified bottlenecks. These strategies may include:
- Code Optimization: Improving the efficiency of the application code.
- Database Optimization: Optimizing database queries and indexing.
- Caching: Implementing caching to reduce response times.
- Resource Allocation: Adjusting the allocation of resources to the application.
- Continuous Monitoring and Improvement: Continuously monitoring application performance and making adjustments as needed. This is an iterative process that ensures that the application remains optimized and efficient.
Network Optimization and Configuration
Network optimization and configuration are critical components of a successful post-migration strategy, directly impacting application performance, security posture, and cost efficiency. Properly configured networks ensure seamless data transfer, minimize latency, and provide a robust foundation for the migrated applications and services. This section delves into best practices, performance tuning strategies, and security measures for optimizing network infrastructure after a migration.
Network Configuration Best Practices
Adhering to established network configuration best practices is paramount for achieving optimal performance and security. These practices encompass various aspects of network design and implementation, ensuring a reliable and efficient network environment.
- Segmenting the Network: Network segmentation involves dividing the network into smaller, isolated subnets based on function or security requirements. This limits the blast radius of potential security breaches and improves overall network performance by reducing broadcast traffic. For instance, separating the database tier from the application tier restricts lateral movement in the event of a compromise.
- Implementing a Consistent Addressing Scheme: A well-defined and consistently applied IP addressing scheme (e.g., using private IP address ranges as defined in RFC 1918) simplifies network management and troubleshooting. Using a structured addressing plan makes it easier to identify and locate network devices.
- Utilizing Quality of Service (QoS): QoS mechanisms prioritize network traffic based on application needs. This ensures that critical traffic, such as voice or video streams, receives preferential treatment, minimizing latency and packet loss. Configuring QoS for database traffic can improve application responsiveness.
- Regularly Updating Network Devices: Keeping network devices, such as routers, switches, and firewalls, updated with the latest firmware and security patches is crucial for mitigating vulnerabilities and ensuring optimal performance. This minimizes exposure to known exploits.
- Documenting Network Configuration: Comprehensive network documentation, including network diagrams, IP address assignments, and device configurations, is essential for troubleshooting, auditing, and change management. This documentation serves as a valuable reference point for network administrators.
- Monitoring Network Performance: Implementing a robust network monitoring system is crucial for identifying performance bottlenecks, detecting anomalies, and proactively addressing potential issues. Monitoring tools should track key metrics like latency, packet loss, and bandwidth utilization.
Examples of Optimizing Network Performance
Optimizing network performance involves a combination of proactive measures and reactive adjustments to ensure efficient data transfer and minimize delays. Several strategies can be employed to enhance network performance.
- Bandwidth Optimization: Bandwidth optimization focuses on maximizing the use of available network bandwidth. Techniques include:
- Caching: Implementing caching mechanisms (e.g., web caches, content delivery networks – CDNs) reduces the load on the network by storing frequently accessed content closer to the users. For example, a CDN can cache static website content, improving loading times for users globally.
- Compression: Compressing data before transmission reduces the amount of data that needs to be transferred, thereby improving network throughput. For example, compressing images and videos can significantly reduce bandwidth consumption.
- Traffic Shaping: Traffic shaping controls the rate at which network traffic is sent, preventing congestion and ensuring fair allocation of bandwidth.
- Latency Reduction: Latency reduction aims to minimize the delay in data transmission. Strategies include:
- Optimizing Routing: Choosing the most efficient routes for data packets reduces the number of hops and overall travel time. Using Border Gateway Protocol (BGP) for routing can dynamically adapt to network conditions.
- Reducing Network Congestion: Minimizing network congestion through QoS, bandwidth management, and proactive monitoring reduces packet loss and retransmissions.
- Proximity to Users: Hosting applications and services closer to the end-users (e.g., using edge computing) reduces the physical distance data needs to travel, thus minimizing latency.
- Load Balancing: Distributing network traffic across multiple servers or network paths prevents any single component from becoming overloaded. Load balancing can be implemented at various levels, including:
- Server Load Balancing: Distributes traffic among multiple servers, ensuring high availability and performance.
- Network Load Balancing: Distributes traffic across multiple network paths, providing redundancy and increased bandwidth.
Methods for Implementing Network Security Measures
Implementing robust network security measures is crucial for protecting migrated applications and data from threats. These measures encompass various techniques to secure network infrastructure and prevent unauthorized access.
- Firewall Configuration: Firewalls act as a barrier between the network and the outside world, controlling network traffic based on predefined rules. Firewall configuration involves:
- Implementing Rule-Based Access Control: Defining rules to allow or deny traffic based on source and destination IP addresses, ports, and protocols.
- Stateful Inspection: Firewalls track the state of network connections, allowing only legitimate traffic to pass through.
- Intrusion Detection and Prevention Systems (IDPS): Integrating IDPS to detect and prevent malicious activity, such as unauthorized access attempts and malware infections.
- Virtual Private Networks (VPNs): VPNs create secure, encrypted connections over public networks, allowing remote users and sites to securely access the network. Implementing VPNs involves:
- Encrypting Data in Transit: VPNs encrypt all data transmitted between the client and the server, protecting it from eavesdropping.
- Authentication: VPNs require users to authenticate before granting access to the network.
- Access Control: VPNs can be configured to restrict access to specific resources or networks.
- Network Segmentation: As previously mentioned, network segmentation isolates different parts of the network, limiting the impact of security breaches. Implementing network segmentation involves:
- Creating Separate VLANs: Virtual LANs (VLANs) logically segment the network, isolating traffic within each VLAN.
- Implementing Micro-segmentation: Micro-segmentation further isolates workloads, even within the same VLAN, using techniques like software-defined networking (SDN).
- Regular Security Audits and Penetration Testing: Conducting regular security audits and penetration testing helps identify vulnerabilities and weaknesses in the network security posture. This involves:
- Vulnerability Scanning: Automated tools scan the network for known vulnerabilities.
- Penetration Testing: Simulated attacks are performed to assess the effectiveness of security controls.
Network Configuration Comparison Table
The following table Artikels different network configurations and their associated pros and cons, enabling informed decision-making during the post-migration optimization phase.
| Network Configuration | Pros | Cons |
|---|---|---|
| Flat Network | Simple to configure and manage, easy to deploy initially. | Poor security, limited scalability, high broadcast traffic, performance bottlenecks. |
| Segmented Network (VLANs) | Improved security, reduced broadcast domains, better performance, easier to manage. | More complex configuration, requires careful planning, potential for inter-VLAN routing overhead. |
| Software-Defined Networking (SDN) | Centralized control, automation, improved agility, enhanced security, fine-grained traffic management. | More complex to implement, requires specialized expertise, potential for vendor lock-in. |
| Zero Trust Network | Strong security posture, least privilege access, reduced attack surface, enhanced visibility. | Highly complex to implement, requires significant planning and resources, potential for performance impact. |
Monitoring, Logging, and Alerting
Post-migration optimization hinges on robust monitoring, logging, and alerting mechanisms. Without these, it becomes exceedingly difficult to diagnose performance bottlenecks, security vulnerabilities, or cost inefficiencies introduced during or after the migration process. Proactive monitoring allows for timely intervention, minimizing downtime and ensuring the migrated environment functions optimally. This section delves into the critical aspects of establishing a comprehensive monitoring and alerting strategy.
Importance of Monitoring Post-Migration
Continuous monitoring is crucial for several reasons after a migration. It provides real-time visibility into the performance, security, and cost-effectiveness of the migrated systems.
- Performance Validation: Monitoring enables the validation of performance metrics against pre-migration baselines. This helps identify performance degradation or improvements, allowing for targeted optimization efforts. For instance, if the response time of a web application increases after migration, monitoring data will pinpoint the cause, such as increased database latency or inefficient code execution.
- Security Posture Assessment: Monitoring provides the ability to detect and respond to security threats. Analyzing logs and monitoring network traffic helps identify unauthorized access attempts, malware infections, and other security incidents. Regular security audits and vulnerability assessments, informed by monitoring data, are essential for maintaining a secure environment.
- Cost Management: Monitoring helps track resource utilization and identify areas for cost optimization. By analyzing resource consumption patterns, organizations can identify opportunities to scale down underutilized resources or right-size instances to reduce cloud spending.
- Compliance Adherence: Monitoring facilitates adherence to regulatory compliance requirements. Logging and auditing capabilities provide the necessary evidence to demonstrate compliance with standards such as GDPR, HIPAA, and PCI DSS.
- Problem Identification and Resolution: Monitoring enables the rapid identification and resolution of issues. By establishing proactive alerts, organizations can be notified of potential problems before they impact users or business operations. This allows for timely intervention and reduces downtime.
Logging and Alerting Best Practices
Effective logging and alerting are fundamental to a successful post-migration monitoring strategy. Implementing best practices ensures that the right data is captured, analyzed, and acted upon promptly.
- Comprehensive Logging: Implement comprehensive logging across all system components, including servers, applications, databases, and network devices. Log events should include timestamps, severity levels, user IDs, and detailed information about the event. Utilize standardized logging formats, such as JSON or Common Event Format (CEF), to facilitate parsing and analysis.
- Centralized Logging: Aggregate logs from all sources into a centralized logging platform. This provides a single pane of glass for monitoring and analysis. Popular centralized logging solutions include the ELK Stack (Elasticsearch, Logstash, Kibana), Splunk, and Graylog.
- Define Alerting Thresholds: Establish clear alerting thresholds based on performance metrics, security events, and cost indicators. These thresholds should be aligned with business requirements and service level agreements (SLAs). Regularly review and adjust thresholds as needed.
- Prioritize Alerts: Categorize alerts based on their severity and impact. High-priority alerts, such as security breaches or critical system failures, should trigger immediate notifications. Lower-priority alerts can be grouped and addressed during scheduled maintenance windows.
- Alerting Channels: Configure multiple alerting channels, such as email, SMS, and incident management systems. Ensure that alerts are routed to the appropriate teams and individuals based on their roles and responsibilities.
- Alert Suppression: Implement alert suppression mechanisms to prevent alert fatigue. Suppress redundant or transient alerts that do not indicate a significant issue.
- Log Rotation and Retention: Establish a log rotation and retention policy that balances the need for historical data with storage costs. Regularly archive and delete older logs according to the retention policy. Consider the requirements of regulatory compliance when determining retention periods.
- Example of Alerting Thresholds: Consider an application server’s CPU utilization. A critical alert could be triggered when CPU utilization consistently exceeds 90% for more than 5 minutes. A warning alert could be triggered when CPU utilization exceeds 75% for more than 15 minutes. These thresholds need to be tuned based on the application’s workload and performance characteristics.
Methods for Analyzing Monitoring Data to Identify Issues
Analyzing monitoring data is crucial for identifying issues and optimizing the migrated environment. Employing various analytical techniques helps uncover performance bottlenecks, security vulnerabilities, and cost inefficiencies.
- Performance Trend Analysis: Analyze performance metrics over time to identify trends and patterns. Look for spikes in resource utilization, response times, or error rates. Compare performance metrics before and after migration to identify performance degradation.
- Correlation Analysis: Correlate different metrics to identify relationships between them. For example, correlate CPU utilization with database query latency to identify database performance bottlenecks. Correlate network traffic with application response times to identify network latency issues.
- Log Analysis: Analyze logs to identify errors, warnings, and informational messages. Use log analysis tools to search for specific events or patterns. Filter logs based on severity, source, and timestamp to narrow down the scope of the analysis.
- Root Cause Analysis: Perform root cause analysis to identify the underlying causes of issues. Use a systematic approach, such as the “5 Whys” technique, to drill down to the root cause.
- Anomaly Detection: Implement anomaly detection techniques to identify unusual behavior. Anomaly detection algorithms can automatically identify deviations from normal patterns, such as sudden spikes in resource utilization or unusual network traffic.
- Benchmarking: Compare performance metrics against industry benchmarks or best practices. Identify areas where performance can be improved.
- Example: If an application’s response time suddenly increases after migration, analysis should include examining CPU usage, memory consumption, database query times, and network latency. If database query times are high, further analysis should focus on database performance, query optimization, and indexing.
Design a System for Automated Incident Response
Automated incident response streamlines the process of responding to incidents, minimizing downtime and reducing the impact of issues. This includes the design of a system that automatically detects issues, triggers alerts, and initiates pre-defined remediation actions.
- Incident Detection and Alerting: The foundation of automated incident response is a robust system for detecting and alerting on incidents. This involves implementing the logging and alerting best practices discussed earlier. Integrate monitoring tools with an incident management system, such as PagerDuty or ServiceNow.
- Runbook Automation: Develop runbooks that Artikel the steps to be taken to resolve common incidents. Automate these runbooks using tools such as Ansible, Chef, or Puppet. Runbooks should include pre-defined remediation actions, such as restarting services, scaling resources, or rolling back changes.
- Automated Remediation: Implement automated remediation actions to resolve incidents automatically. This could include scaling resources, restarting services, or patching vulnerabilities. Automated remediation should be carefully designed and tested to avoid unintended consequences.
- Orchestration and Workflow: Use orchestration tools to automate the execution of runbooks and workflows. Orchestration tools can trigger automated remediation actions based on alerts and events. Integrate orchestration tools with the incident management system to automate the incident resolution process.
- Integration with ChatOps: Integrate incident response with ChatOps platforms, such as Slack or Microsoft Teams. This enables teams to collaborate on incident resolution in real-time. ChatOps can be used to trigger automated remediation actions, provide status updates, and document incident resolution steps.
- Feedback Loop and Continuous Improvement: Implement a feedback loop to continuously improve the incident response process. Analyze incidents to identify areas for improvement. Update runbooks and automated remediation actions based on lessons learned. Conduct post-incident reviews to identify root causes and prevent future incidents.
- Example: If a server’s CPU utilization consistently exceeds a defined threshold, an automated response could include triggering an alert, scaling up the server resources, and notifying the on-call team via Slack.
Automation and Infrastructure as Code (IaC)
Post-migration optimization heavily relies on automating repetitive tasks and managing infrastructure efficiently. Implementing automation reduces human error, accelerates deployments, and enables consistent configurations across environments. This shift from manual processes to automated systems is crucial for maintaining performance, controlling costs, and ensuring security after a migration.
Benefits of Automation in Post-Migration Optimization
Automation offers significant advantages throughout the post-migration phase. It streamlines processes, improves efficiency, and enhances overall system reliability.
* Reduced Operational Costs: Automation minimizes manual intervention, decreasing the need for human resources dedicated to repetitive tasks, which translates into lower operational expenses.
– Improved Deployment Speed: Automated deployments significantly reduce the time required to provision and configure resources, allowing for faster iterations and quicker response times to changing demands.
– Increased Consistency and Reliability: Automation ensures consistent configurations across all environments, reducing the risk of configuration drift and human error, leading to more reliable systems.
– Enhanced Scalability and Elasticity: Automated infrastructure can scale resources up or down dynamically based on demand, ensuring optimal performance and cost efficiency.
– Faster Troubleshooting and Recovery: Automated processes facilitate faster identification and resolution of issues, as well as automated recovery mechanisms in case of failures.
IaC Tools and Use Cases
Infrastructure as Code (IaC) tools allow for defining and managing infrastructure in a declarative manner using code. This approach enables version control, repeatability, and automation of infrastructure provisioning. Several tools are available, each with its strengths and specific use cases.
* Terraform: Terraform, developed by HashiCorp, is a popular IaC tool known for its ability to manage infrastructure across multiple cloud providers (AWS, Azure, GCP, etc.) and on-premises environments. It uses a declarative configuration language (HCL – HashiCorp Configuration Language) to define infrastructure resources.
– Use Case: Automating the creation and management of virtual networks, compute instances, storage buckets, and other resources across different cloud platforms. For example, a company migrating its applications to AWS can use Terraform to provision all necessary resources, including VPCs, subnets, EC2 instances, security groups, and load balancers.
– AWS CloudFormation: CloudFormation is a native IaC service provided by Amazon Web Services.
It allows users to define and provision AWS resources using templates written in JSON or YAML.
– Use Case: Deploying and managing complex AWS architectures, such as serverless applications, containerized workloads, and database clusters. For instance, a team can use CloudFormation to deploy a complete web application stack, including an API Gateway, Lambda functions, DynamoDB tables, and S3 buckets.
– Azure Resource Manager (ARM) Templates: ARM templates are Microsoft’s IaC solution for Azure. They use JSON or Bicep (a declarative language) to define Azure resources.
– Use Case: Automating the deployment and management of Azure services, such as virtual machines, virtual networks, storage accounts, and databases. A business could use ARM templates to provision a highly available virtual machine environment with load balancing, autoscaling, and monitoring capabilities.
– Google Cloud Deployment Manager: Deployment Manager is Google Cloud’s IaC tool, allowing users to define and deploy Google Cloud resources using YAML, Python, or Jinja2 templates.
– Use Case: Automating the creation and management of Google Cloud resources, including virtual machines, Kubernetes clusters, and Cloud Storage buckets. A data science team can use Deployment Manager to deploy a machine learning environment with Compute Engine instances, Cloud Storage for data storage, and Cloud ML Engine for model training and deployment.
– Ansible: Ansible is an open-source automation tool that uses a simple, human-readable language (YAML) to automate configuration management, application deployment, and orchestration.
– Use Case: Automating the configuration of servers, deploying applications, and orchestrating complex workflows across different environments. For example, a company can use Ansible to install and configure web servers, database servers, and application servers after a migration.
Methods for Automating Resource Provisioning and Management
Automating resource provisioning and management involves various techniques to ensure efficient and consistent infrastructure deployment and maintenance. These methods reduce manual effort, improve reliability, and accelerate the overall process.
* IaC Pipelines: Integrating IaC tools with CI/CD pipelines enables automated provisioning and configuration of infrastructure. When code changes are committed, the pipeline can trigger IaC tools to update the infrastructure.
– Configuration Management Tools: Tools like Ansible, Chef, and Puppet can be used to automate the configuration of servers and applications, ensuring consistency across environments.
– API-Driven Automation: Using APIs provided by cloud providers and other services allows for programmatic control over resources, enabling automation of tasks such as scaling, monitoring, and troubleshooting.
– Orchestration Tools: Orchestration tools like Kubernetes and Docker Swarm automate the deployment, scaling, and management of containerized applications.
– Automated Testing: Implementing automated tests, such as infrastructure tests and application tests, verifies the correctness of the infrastructure and applications after a migration.
Common IaC Practices
Successful implementation of IaC involves adopting specific practices to ensure efficiency, reliability, and maintainability.
* Version Control: Store IaC code in a version control system (e.g., Git) to track changes, collaborate effectively, and enable rollback capabilities.
– Modularity: Break down infrastructure definitions into reusable modules to promote code reuse and reduce redundancy.
– Testing: Implement testing strategies, including unit tests and integration tests, to validate the IaC code and ensure that infrastructure deployments are reliable.
– Documentation: Document IaC code and infrastructure designs to provide clarity, facilitate collaboration, and ensure maintainability.
– Security Best Practices: Incorporate security best practices, such as least privilege access and encryption, into IaC code to protect infrastructure from vulnerabilities.
– Collaboration: Foster collaboration among teams (e.g., developers, operations, security) to ensure that IaC aligns with business needs and organizational goals.
– Idempotency: Ensure that IaC code is idempotent, meaning that running the same code multiple times yields the same result.
– Automated Testing: Implement automated testing to validate infrastructure changes. This includes testing for functionality, performance, and security.
– Infrastructure as Code Reviews: Implement a code review process to ensure the quality and correctness of the IaC code.
This helps to catch errors and enforce best practices.
– Continuous Integration and Continuous Delivery (CI/CD): Integrate IaC with CI/CD pipelines to automate the deployment of infrastructure changes.
Iterative Improvement and Continuous Optimization
Post-migration optimization is not a one-time event but an ongoing process. The cloud environment is dynamic, and continuous optimization ensures that the benefits of migration are sustained and enhanced over time. This iterative approach allows organizations to adapt to changing business needs, technological advancements, and evolving security threats.
Importance of Continuous Improvement
Continuous improvement is essential for maximizing the return on investment (ROI) of a cloud migration. It helps to maintain optimal performance, control costs, enhance security, and adapt to evolving business requirements. Without a commitment to continuous improvement, cloud environments can degrade over time, leading to increased costs, decreased performance, and potential security vulnerabilities.
- Sustained Performance: Continuous optimization ensures that applications and infrastructure continue to perform at optimal levels. Regular monitoring and tuning address performance bottlenecks, ensuring a smooth user experience.
- Cost Efficiency: Cloud costs are variable. Continuous optimization allows for ongoing cost analysis and the implementation of strategies to reduce unnecessary spending, such as rightsizing instances, utilizing reserved instances, and leveraging spot instances.
- Enhanced Security: Security threats evolve constantly. Continuous improvement includes regularly reviewing and updating security configurations, patching vulnerabilities, and implementing the latest security best practices to protect against emerging threats.
- Adaptability: The business landscape is constantly changing. Continuous optimization allows organizations to adapt to new business requirements, scale resources as needed, and take advantage of new cloud services and features.
Methods for Establishing Feedback Loops
Establishing effective feedback loops is critical for identifying areas for improvement and driving continuous optimization. These loops involve gathering data, analyzing it, implementing changes, and measuring the results.
- Monitoring and Alerting: Implement comprehensive monitoring tools to track key performance indicators (KPIs) such as CPU utilization, memory usage, network latency, and error rates. Set up alerts to notify teams of any anomalies or performance degradations.
- User Feedback: Collect feedback from users through surveys, feedback forms, and direct communication channels. This provides valuable insights into the user experience and helps identify areas where performance or functionality can be improved.
- Incident Management: Establish a robust incident management process to quickly identify, investigate, and resolve issues. Analyze incident data to identify recurring problems and implement preventative measures.
- Performance Testing: Regularly conduct performance tests to simulate real-world user loads and identify performance bottlenecks. This can include load testing, stress testing, and endurance testing.
- Regular Reviews and Audits: Conduct regular reviews of the cloud environment, including cost analysis, security audits, and performance assessments. These reviews should involve stakeholders from different teams, such as operations, development, and security.
Strategies for Regularly Reviewing and Optimizing the Environment
Regularly reviewing and optimizing the cloud environment involves a systematic approach to identify and address areas for improvement. This includes a combination of automated processes and manual reviews.
- Automated Monitoring and Analysis: Utilize automated monitoring tools to continuously track key performance indicators (KPIs) and identify anomalies. Implement automated analysis to detect trends and potential issues.
- Regular Cost Reviews: Conduct regular cost reviews to identify areas where costs can be reduced. This includes analyzing resource utilization, identifying idle resources, and optimizing instance types. For example, Amazon Web Services (AWS) provides Cost Explorer and Cost Anomaly Detection to analyze and optimize costs.
- Security Audits and Vulnerability Assessments: Conduct regular security audits and vulnerability assessments to identify and address security vulnerabilities. This includes scanning for misconfigurations, patching vulnerabilities, and reviewing security policies.
- Performance Tuning: Regularly review and tune application and infrastructure performance. This includes optimizing database queries, caching data, and adjusting instance sizes.
- Infrastructure as Code (IaC) Updates: Maintain infrastructure as code (IaC) to ensure consistency and repeatability. Regularly update IaC templates to reflect changes in the environment and implement best practices.
- Technology Stack Updates: Regularly update the technology stack, including operating systems, databases, and application frameworks, to leverage the latest features, security patches, and performance improvements.
Demonstrating How to Measure the Effectiveness of Optimization Efforts
Measuring the effectiveness of optimization efforts is crucial for demonstrating the value of continuous improvement and justifying ongoing investments. This involves establishing clear metrics, tracking performance over time, and comparing results before and after optimization.
- Key Performance Indicators (KPIs): Define specific KPIs to measure the effectiveness of optimization efforts. These KPIs should align with the goals of the optimization initiatives, such as improved performance, reduced costs, and enhanced security.
- Baseline Performance: Establish a baseline performance before implementing any optimization changes. This provides a reference point for comparing results after optimization.
- Before-and-After Comparisons: Compare the performance of the environment before and after optimization efforts. This can include comparing KPIs such as CPU utilization, memory usage, network latency, and cost.
- Trend Analysis: Analyze trends over time to identify patterns and assess the long-term impact of optimization efforts. This includes tracking KPIs over weeks, months, or even years.
- Cost Savings Analysis: Quantify the cost savings achieved through optimization efforts. This includes tracking reductions in resource usage, the utilization of reserved instances, and the implementation of cost-saving strategies.
- User Satisfaction Surveys: Use user satisfaction surveys to gauge the impact of optimization efforts on the user experience. Measure metrics such as page load times, application responsiveness, and overall satisfaction.
Last Word
In conclusion, a post-migration optimization strategy is a multifaceted discipline that is essential for realizing the full benefits of any migration effort. It goes beyond the technical aspects of the move, requiring a holistic view of performance, cost, security, and operational efficiency. By embracing a continuous improvement mindset and leveraging automation, organizations can ensure their migrated environments are not only functional but also optimized for long-term success, providing the agility and scalability needed in today’s dynamic technological landscape.
The ongoing assessment and refinement of these strategies are paramount for sustained operational excellence.
Commonly Asked Questions
What is the primary goal of a post-migration optimization strategy?
The primary goal is to ensure the migrated environment functions optimally, leveraging the full potential of the new infrastructure while minimizing operational expenses and maintaining a robust security posture.
How does post-migration optimization differ from pre-migration planning?
Pre-migration planning focuses on assessing the current environment and planning the migration process. Post-migration optimization focuses on refining the migrated environment after the migration is complete, addressing issues that may not have been apparent before or that arose during the move.
What are some common metrics to monitor during post-migration optimization?
Common metrics include CPU utilization, memory usage, disk I/O, network latency, error rates, and application response times. Monitoring these metrics helps identify performance bottlenecks and areas for improvement.
How often should post-migration optimization be performed?
Post-migration optimization should be an ongoing process, not a one-time event. Continuous monitoring, regular reviews, and iterative improvements are crucial for maintaining optimal performance and cost efficiency.